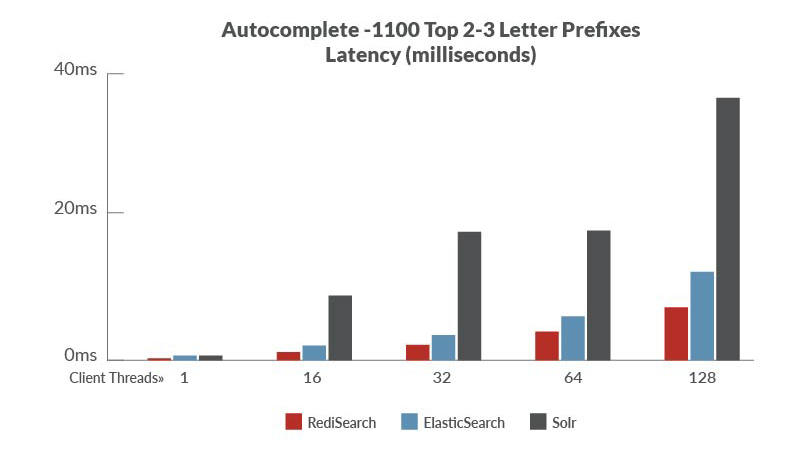
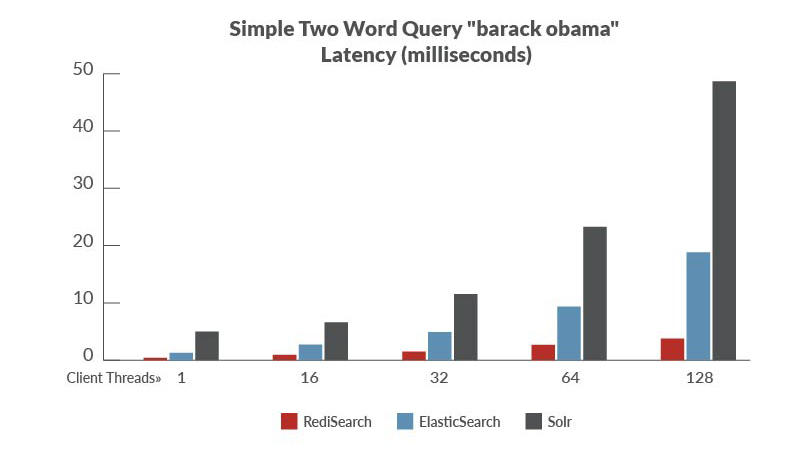
当我们使用持续集成Jenkins的时候经常会结合一系列的插件使用,这里就说一下Jenkins集成Sonar做代码质量管理以及Junit(testng)、JaCoCo做单元测试和覆盖率的时候遇到的问题。
前提
首先我们的工程使用maven构建,单元测试使用testng编写,在使用jenkins之前我们应该在本地使用maven调通所有的单元测试以及test coverage的问题。
我们使用maven-surefire-plugin来生成单元测试报告,使用jacoco-maven-plugin来生成test coverage报告。下面我给出以下我使用的标准配置
maven工程调通单元测试以及测试覆盖率报告生成
pom.xml的标准配置
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.4</version>
<scope>test</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skipTests>false</skipTests>
<argLine>${argLine} -Dfile.encoding=UTF-8</argLine>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-deploy-plugin</artifactId>
<configuration>
<skip>false</skip>
</configuration>
</plugin>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.1</version>
<configuration>
<skip>false</skip>
</configuration>
<executions>
<execution>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<configuration>
<outputDirectory>${basedir}/target/coverage-reports</outputDirectory>
</configuration>
<id>report</id>
<phase>test</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
根据上面配置执行下来的报告生成的目录结构如下:

classes是源代码编译生成的字节码目录coverage-reports是单元测试覆盖率报告生成目录surefire-reports是单元测试报告生成目录test-classes是单元测试代码编译生成的字节码目录jacoco.exec是用于生成单元测试可执行文件
下面我说一下我们会遇到的常规问题
上步操作会遇到的常规问题
问题一:Tests are skipped.
[INFO] --- maven-surefire-plugin:2.5:test (default-test) @ tools ---
[INFO] Tests are skipped.
单元测试被跳过,这个可以通过maven-surefire-plugin插件的configuration来配置不跳过,如下配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skipTests>false</skipTests>
</configuration>
</plugin>
配置skipTests属性而不是skip属性这里需要注意一下,有很多人配置的skip属性
问题二:单元测试输出乱码
-------------------------------------------------------
T E S T S
-------------------------------------------------------
Running TestSuite
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
=====��һ��===============
=====��һ��===============
=====���¼���===============
单元测试输出信息乱码,这个可以通过maven-surefire-plugin插件的configuration来配置字符编码,如下配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skipTests>false</skipTests>
<argLine>-Dfile.encoding=UTF-8</argLine>
</configuration>
</plugin>
到这里我们就可以去taget/surefire-reports目录下查看单元测试报告。
问题三:Skipping JaCoCo execution due to missing execution data file.
[INFO] --- jacoco-maven-plugin:0.8.1:report (report) @ tools ---
[INFO] Skipping JaCoCo execution due to missing execution data file.
jacoco执行被跳过,原因是没有找到jacoco可执行文件jacoco.exec。
这个时候我们去target目录下是看不到jacoco.exec文件的,有的版本名字叫jacoco-junit.exec。
理论上执行的时候会自动生成exec文件,但是为什么没有生成?我们看一下执行日志
[INFO] --- jacoco-maven-plugin:0.8.1:prepare-agent (default) @ tools ---
[INFO] argLine set to -javaagent:D:\\javatools\\mvnrepository\\org\\jacoco\\org.jacoco.agent\\0.8.1\\org.jacoco.agent-0.8.1-runtime.jar=destfile=D:\\javatools\\workspace\\framework\\tools\\target\\jacoco.exec
jacoco.exec的生成是根据-javaagent的方式来生成的,我们有可以看到jacoco-maven-plugin指定了argLine参数,但是为什么没有生效?
原因是我们上面指定过单元测试编码,使用的就是argLine参数,因此这个问题应该是上面的编码参数指定后没有带入插件添加的-javaagent参数,那如何解决?查看下面配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.5</version>
<configuration>
<skipTests>false</skipTests>
<argLine>${argLine} -Dfile.encoding=UTF-8</argLine>
</configuration>
</plugin>
在argLine中增加变量${argLine}后面再增加自动以的参数
如果通过配置手动的指定jacoco.exec文件的生成路径也需要注意也可能会出现这个问题,生成exec的路径指定在哪里,report执行的时候就需要通过dataFile来指定exec的路径,让程序知道正确的exec路径,比如说:
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.1</version>
<configuration>
<skip>false</skip>
<destFile>${basedir}/target/coverage-reports/jacoco.exec</destFile>
</configuration>
<executions>
<execution>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<configuration>
<dataFile>${basedir}/target/coverage-reports/jacoco.exec</dataFile>
<outputDirectory>${basedir}/target/coverage-reports</outputDirectory>
</configuration>
<id>report</id>
<phase>test</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>
上面通过configuration的destFile来自定义jacoco.exec的生成路径,下面在report的时候需要通过dataFile来指定对应的jacoco.exec的路径。
Jenkins使用JaCoCo plugin插件
首先去Jenkins上安装JaCoCo plugin插件,插件的安装就跳过了,插件安装好后,在job中如何配置?
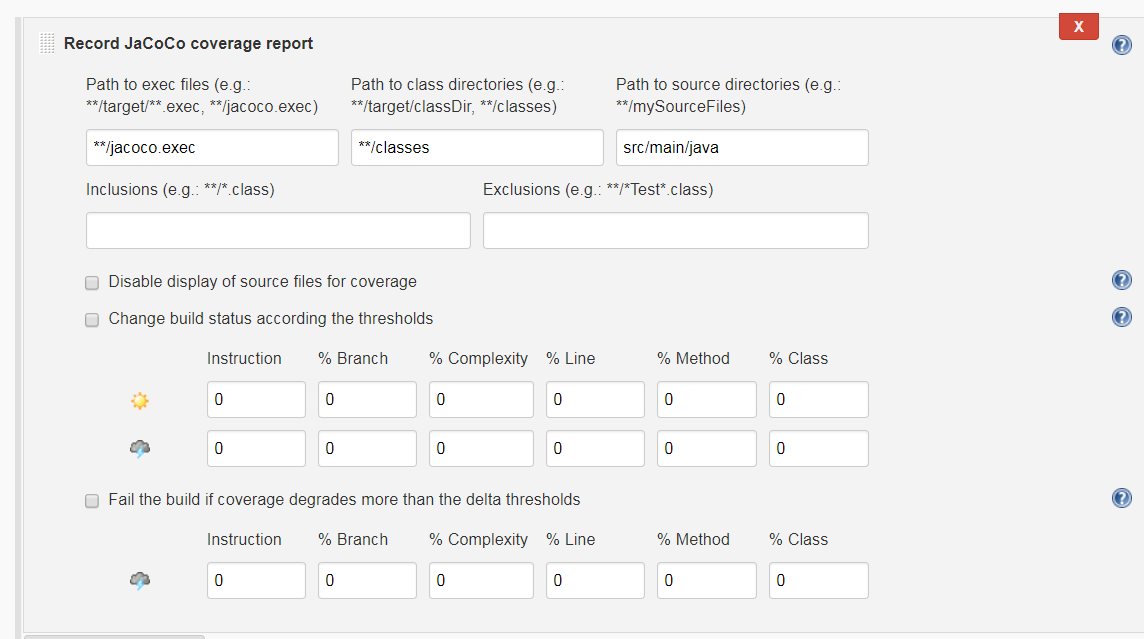
这里需要注意的配置
- Path to exec files: **/jacoco.exec 可执行文件路径
- Path to class directories: 这个配置的是源代码编译后的字节码目录,也就是
classes目录不是test-classes目录,如果有多个可以指定多个
- Path to source directories: 这个配置的是源代码的目录,也就是
src/main/java目录,如果有多个可以指定多个。
配置好之后执行job会看到如下的日志:
INFO: ------------------------------------------------------------------------
Injecting SonarQube environment variables using the configuration: SonarQube
[JaCoCo plugin] Collecting JaCoCo coverage data...
[JaCoCo plugin] **/jacoco.exec;**/classes;src/main/java; locations are configured
Injecting SonarQube environment variables using the configuration: SonarQube
Injecting SonarQube environment variables using the configuration: SonarQube
[JaCoCo plugin] Number of found exec files for pattern **/jacoco.exec: 1
[JaCoCo plugin] Saving matched execfiles: /var/lib/jenkins/workspace/cc-framework-tools/target/coverage-reports/jacoco.exec
[JaCoCo plugin] Saving matched class directories for class-pattern: **/classes:
[JaCoCo plugin] - /var/lib/jenkins/workspace/cc-framework-tools/target/classes 5 files
[JaCoCo plugin] Saving matched source directories for source-pattern: src/main/java:
[JaCoCo plugin] - /var/lib/jenkins/workspace/cc-framework-tools/src/main/java 5 files
[JaCoCo plugin] Loading inclusions files..
[JaCoCo plugin] inclusions: []
[JaCoCo plugin] exclusions: []
[JaCoCo plugin] Thresholds: JacocoHealthReportThresholds [minClass=0, maxClass=0, minMethod=0, maxMethod=0, minLine=0, maxLine=0, minBranch=0, maxBranch=0, minInstruction=0, maxInstruction=0, minComplexity=0, maxComplexity=0]
[JaCoCo plugin] Publishing the results..
[JaCoCo plugin] Loading packages..
[JaCoCo plugin] Done.
[JaCoCo plugin] Overall coverage: class: 50, method: 54, line: 48, branch: 40, instruction: 55
Finished: SUCCESS
出现上面日志就证明配置成功并且可以看到报告,如果出现下面的日志就证明配置的目录没有扫到classes,需要修改Path to class directories目录的配置
Overall coverage: class: 0, method: 0, line: 0, branch: 0, instruction: 0
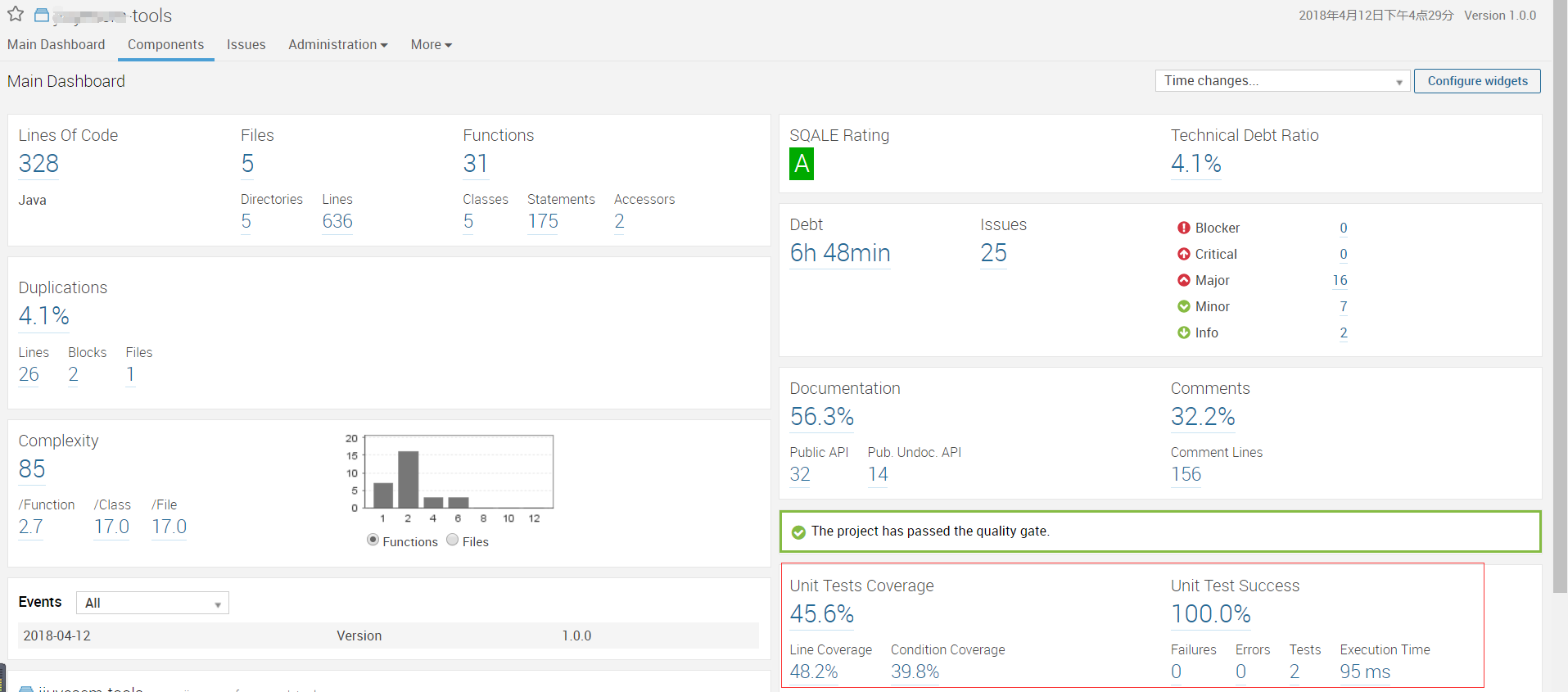
最终结果如下图:

Jenkins使用Sonarqube plugin插件
首先去Jenkins上安装SonarQube plugin插件,插件的安装就跳过了,插件安装好后,在jenkins的系统配置中配置sonar服务器信息,如下
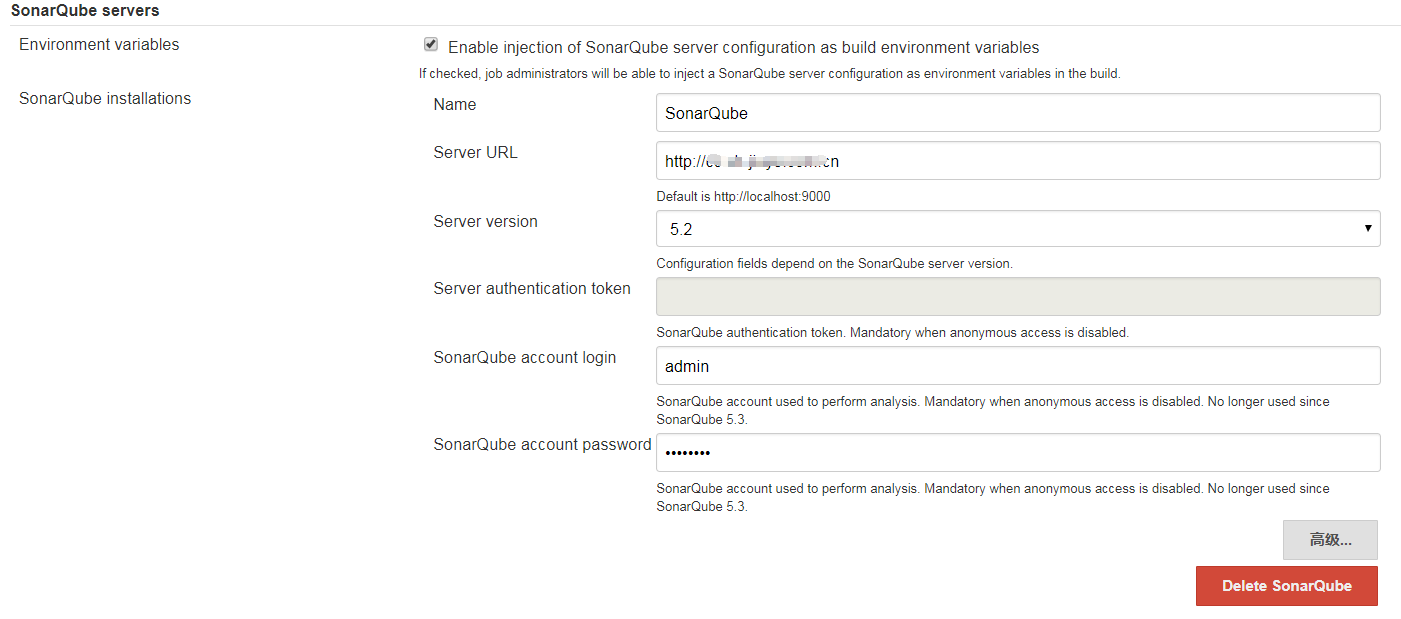
配置好后在job的配置中增加SonarQube的支持,如下
- 在构建环境下添加
Prepare SonarQube Scanner environment
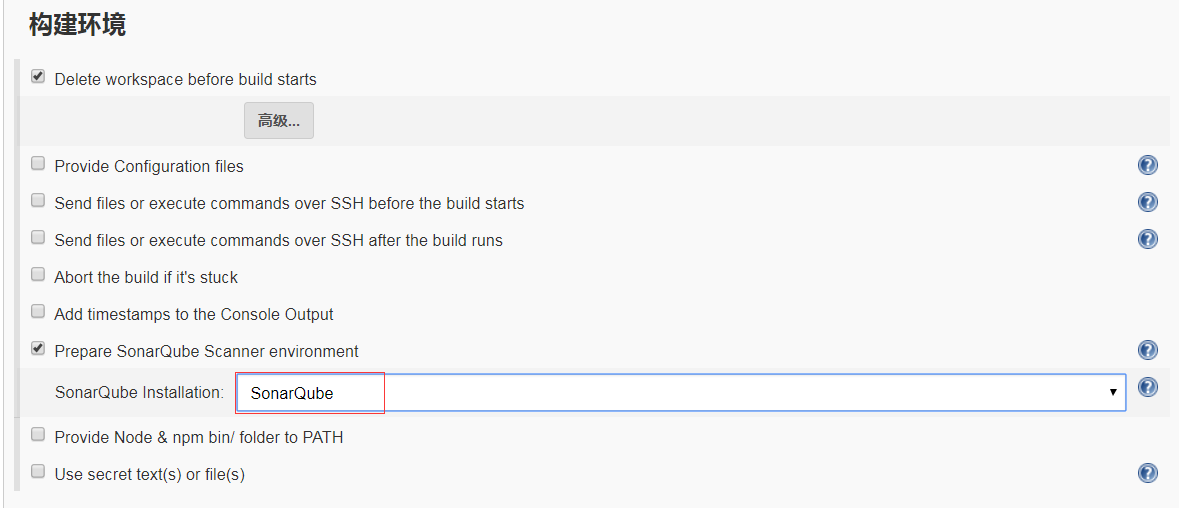
- 在构建下添加
Execute SonarQube Scanner
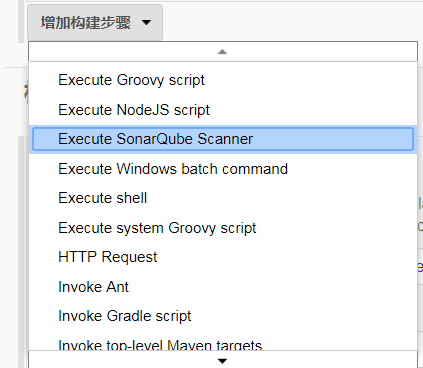
- 在
Execute SonarQube Scanner中增加Analysis properties
# required metadata
# 项目key
sonar.projectKey=com.domian.package:projectName
# 项目名称
sonar.projectName=tools
# 项目版本,可以写死,也可以引用变量
sonar.projectVersion=${VER}
# 源文件编码
sonar.sourceEncoding=UTF-8
# 源文件语言
sonar.language=java
# path to source directories (required)
# 源代码目录,如果多个使用","分割 例如:mode1/src/main,mode2/src/main
sonar.sources=src/main
# 单元测试目录,如果多个使用","分割 例如:mode1/src/test,mode2/src/test
sonar.tests=src/test
# Exclude the test source
# 忽略的目录
#sonar.exclusions=*/src/test/**/*
# 单元测试报告目录
sonar.junit.reportsPath=target/surefire-reports
# 代码覆盖率插件
sonar.java.coveragePlugin=jacoco
# jacoco.exec文件路径
sonar.jacoco.reportPath=target/coverage-reports/jacoco.exec
# 这个没搞懂,官方示例是配置成jacoco.exec文件路径
sonar.jacoco.itReportPath=target/coverage-reports/jacoco.exec
具体的参数可以查看官方文档:《Analysis Parameters》
配置好之后执行job后去Sonar上只看到了单元测试的信息,没有看到单元测试覆盖率的信息,关于这个问题我们分析job执行的日志,如下:
问题一:No JaCoCo analysis of project coverage can be done since there is no class files.
16:01:17.455 INFO - Sensor JaCoCoOverallSensor
16:01:17.470 INFO - Analysing /var/lib/jenkins/workspace/cc-framework-tools/target/coverage-reports/jacoco.exec
16:01:17.481 INFO - No JaCoCo analysis of project coverage can be done since there is no class files.
16:01:17.481 INFO - Sensor JaCoCoOverallSensor (done) | time=26ms
16:01:17.482 INFO - Sensor JaCoCoSensor
16:01:17.482 INFO - No JaCoCo analysis of project coverage can be done since there is no class files.
16:01:17.482 INFO - Sensor JaCoCoSensor (done) | time=0ms
16:01:17.482 INFO - Sensor Code Colorizer Sensor
说的是没找到class文件所以jacoco不能进行分析,问题很明显是没有找到class类,难道它不是去maven标准的target/classes下找文件么?
但是找到了这篇文章:《Jenkins, JaCoCo, and SonarQube Integration With Maven》,看到里面在pom.xml中配置了一些参数给我了启发,发现有个参数sonar.binaries指定的是classes目录,可以插件的有些参数不兼容maven,在官方的配置中可以看到这样的字样: Not compatible with Mave和Compatible with Maven,能看到有写参数兼容maven默认路径有些不兼容。
随后再官方文档中也找到了与jenkins继承的properties配置说明:《Triggering Analysis on Hudson Job》
# path to project binaries (optional), for example directory of Java bytecode
# java字节码目录
sonar.binaries=binDir
最终给出Execute SonarQube Scanner中的Analysis properties完成配置参数如下:
# required metadata
# 项目key
sonar.projectKey=com.domian.package:projectName
# 项目名称
sonar.projectName=tools
# 项目版本,可以写死,也可以引用变量
sonar.projectVersion=${VER}
# 源文件编码
sonar.sourceEncoding=UTF-8
# 源文件语言
sonar.language=java
# path to source directories (required)
# 源代码目录,如果多个使用","分割 例如:mode1/src/main,mode2/src/main
sonar.sources=src/main/java
# 单元测试目录,如果多个使用","分割 例如:mode1/src/test,mode2/src/test
sonar.tests=src/test/java
# java字节码目录
sonar.binaries=target/classes
# 单元测试报告目录
sonar.junit.reportsPath=target/surefire-reports
# 代码覆盖率插件
sonar.java.coveragePlugin=jacoco
# jacoco插件版本
jacoco.version=0.8.1
# jacoco.exec文件路径
sonar.jacoco.reportPath=target/coverage-reports/jacoco.exec
全部配置修改完后执行job后去Sonar上查看具体的信息如下: