使用Embedded RedisServer写UT
当我们在进行开发的时候经常会用到Redis,但是在写junit的时候往往引用了Redis造成test case很难写,我们需要mock一个localhost的Redis server来进行测试,因此我们可以借助embedded redisServer来实现,下面我们就看一下具体使用的示例
代码示例
@Before
public void setUp() throws IOException {
initMocks(this);
final Random random = new SecureRandom();
redisServer = new RedisServer();
redisServer.start();
pool = new JedisPool();
repository = new RedisKeyRepository(pool);
manager = new RedisKeyManager(random, pool, repository);
manager.setMaxActiveKeys(3);
clearData();
manager.initialiseNewRepository();
resource = new ProtectedResource(repository, random);
}
这是一个非常简单的使用示例,我们还可以更改配置以及增加密码
@Before
public void setUpRedis() throws IOException, SchedulerConfigException {
port = getPort();
logger.debug("Attempting to start embedded Redis server on port " + port);
redisServer = RedisServer.builder()
.port(port)
.build();
redisServer.start();
final short database = 1;
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(jedisPoolConfig, host, port, Protocol.DEFAULT_TIMEOUT, null, database);
jobStore = new RedisJobStore();
jobStore.setHost(host);
jobStore.setLockTimeout(2000);
jobStore.setPort(port);
jobStore.setInstanceId("testJobStore1");
jobStore.setDatabase(database);
mockScheduleSignaler = mock(SchedulerSignaler.class);
jobStore.initialize(null, mockScheduleSignaler);
schema = new RedisJobStoreSchema();
jedis = jedisPool.getResource();
jedis.flushDB();
}
使用RedisServerBuilder构建Redis server,并且指定port
@Test
//Note the try/finally is to ensure that the server is shutdown so other tests do not have to
//provide auth information
public void testAuth() throws Exception {
RedisServer server = RedisServer.builder().port(6381).setting("requirepass foobar").build();
server.start();
RedisOptions job = new RedisOptions()
.setHost("localhost")
.setPort(6381);
RedisClient rdx = RedisClient.create(vertx, job);
rdx.auth("barfoo", reply -> {
assertFalse(reply.succeeded());
rdx.auth("foobar", reply2 -> {
assertTrue(reply2.succeeded());
try {
server.stop();
} catch (Exception ignore) {
}
testComplete();
});
});
await();
}
设置一个需要密码访问的Redis server,setting可以设置redis conf中的所有属性
更多用法
还有很多用法,具体查看下面的代码示例
@Test
public void testDebugSegfault() throws Exception {
RedisServer server = RedisServer.builder().port(6381).build();
server.start();
RedisOptions job = new RedisOptions()
.setHost("localhost")
.setPort(6381);
RedisClient rdx = RedisClient.create(vertx, job);
rdx.debugSegfault(reply -> {
// this should fail, since we crashed the server on purpose
assertTrue(reply.failed());
rdx.info(reply2 -> {
assertFalse(reply2.succeeded());
server.stop();
testComplete();
});
});
await();
}
public RedisServerResource(int port, String password) {
this.port = port;
try {
RedisExecProvider redisExecProvider = RedisExecProvider.defaultProvider();
this.redisServer = RedisServer
.builder()
.redisExecProvider(redisExecProvider)
.port(port)
.setting("requirepass " + password)
.build();
} catch (Throwable error) {
String message = String.format("failed creating Redis server (port=%d)", port);
throw new RuntimeException(message, error);
}
}
@Before
public void before() throws Exception {
mockTracer.reset();
redisServer = RedisServer.builder().setting("bind 127.0.0.1").build();
redisServer.start();
}
private void startServer(TestContext testContext) {
EmbeddedRedis embeddedRedis = AnnotationUtils.findAnnotation(testContext.getTestClass(), EmbeddedRedis.class);
int port = embeddedRedis.port();
try {
server = new RedisServer(port);
server.start();
} catch (IOException e) {
if (logger.isErrorEnabled()) {
logger.error(e.getMessage(), e);
}
}
}
private RedisServer createRedisServer() {
final RedisServerBuilder redisServerBuilder = RedisServer.builder()
.port(redisPort)
.setting("appendonly yes")
.setting("appendfsync everysec");
settings.stream().forEach(s -> redisServerBuilder.setting(s));
final RedisServer redisServer = redisServerBuilder.build();
return redisServer;
}
有可能我们启动会遇到下面的错误:
java.lang.RuntimeException: Can't start redis server. Check logs for details.
at redis.embedded.AbstractRedisInstance.awaitRedisServerReady(AbstractRedisInstance.java:66)
at redis.embedded.AbstractRedisInstance.start(AbstractRedisInstance.java:37)
at redis.embedded.RedisServer.start(RedisServer.java:11)
at com.bignibou.configuration.session.EmbeddedRedisConfiguration$RedisServerBean.afterPropertiesSet(EmbeddedRedisConfiguration.java:26)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1633)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1570)
... 15 more
这个是什么原因呢?我们进一步debug输出redis server的log看是什么问题,redis log如下:
The windows version of redis allocates a large memory mapped file for sharing the heap with the forked process used in persistence operations. This file will be created in the current working directory or the directory specified by the 'heapdir' directive in the
.conf file. Windows is reporting that there is insufficient disk space available for this file (Windows error 0x70).
You may fix this probilem by either reducing the size of the Redis heap with the --maxheap flag, or by moving the heap file to a local drive with sufficient space.
Please see the documentation included with the binary distributions for more details on the --maxheap and --heapdir flags.
Redis can not continue, Exiting.
这里的原因是我们启动的时候heap不够,redis server默认的maxheap:1024000000,创建.conf文件时硬盘不够,那如何解决这个错误呢?
@Test
public void testAuth() throws Exception {
RedisServer server = RedisServer.builder().port(6381).setting("maxheap 51200000").build();
server.start();
}
关于redis maxheap的详细描述如下:
# The Redis heap must be larger than the value specified by the maxmemory
# flag, as the heap allocator has its own memory requirements and
# fragmentation of the heap is inevitable. If only the maxmemory flag is
# specified, maxheap will be set at 1.5*maxmemory. If the maxheap flag is
# specified along with maxmemory, the maxheap flag will be automatically
# increased if it is smaller than 1.5*maxmemory.
#
# maxheap <bytes>
maxheap 51200000
注意:修改时需要考虑可用量,常规情况都无需修改这个参数


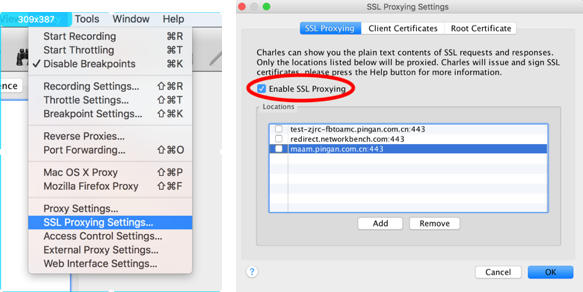
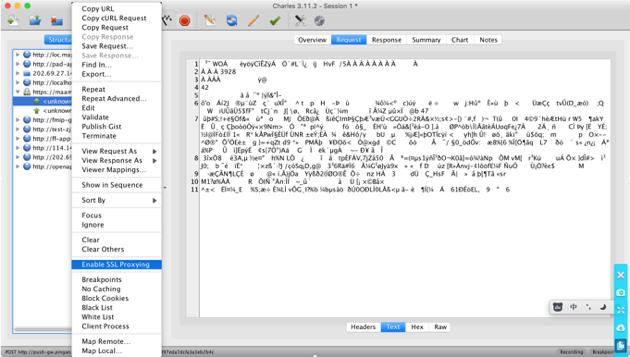
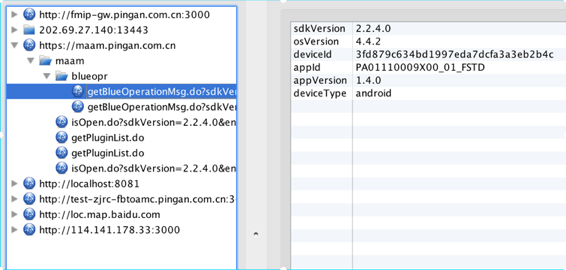
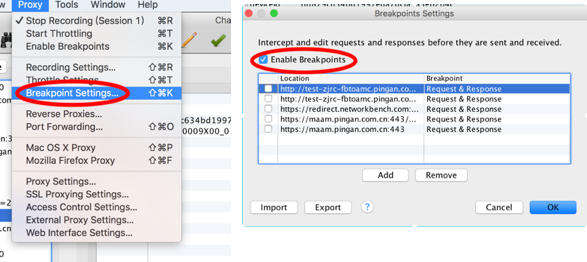
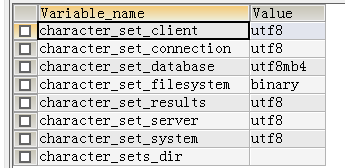
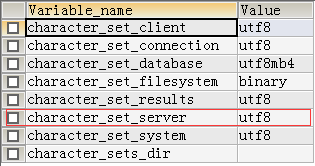
 这个字上,首先先让我们看这个字的字符信息
这个字上,首先先让我们看这个字的字符信息