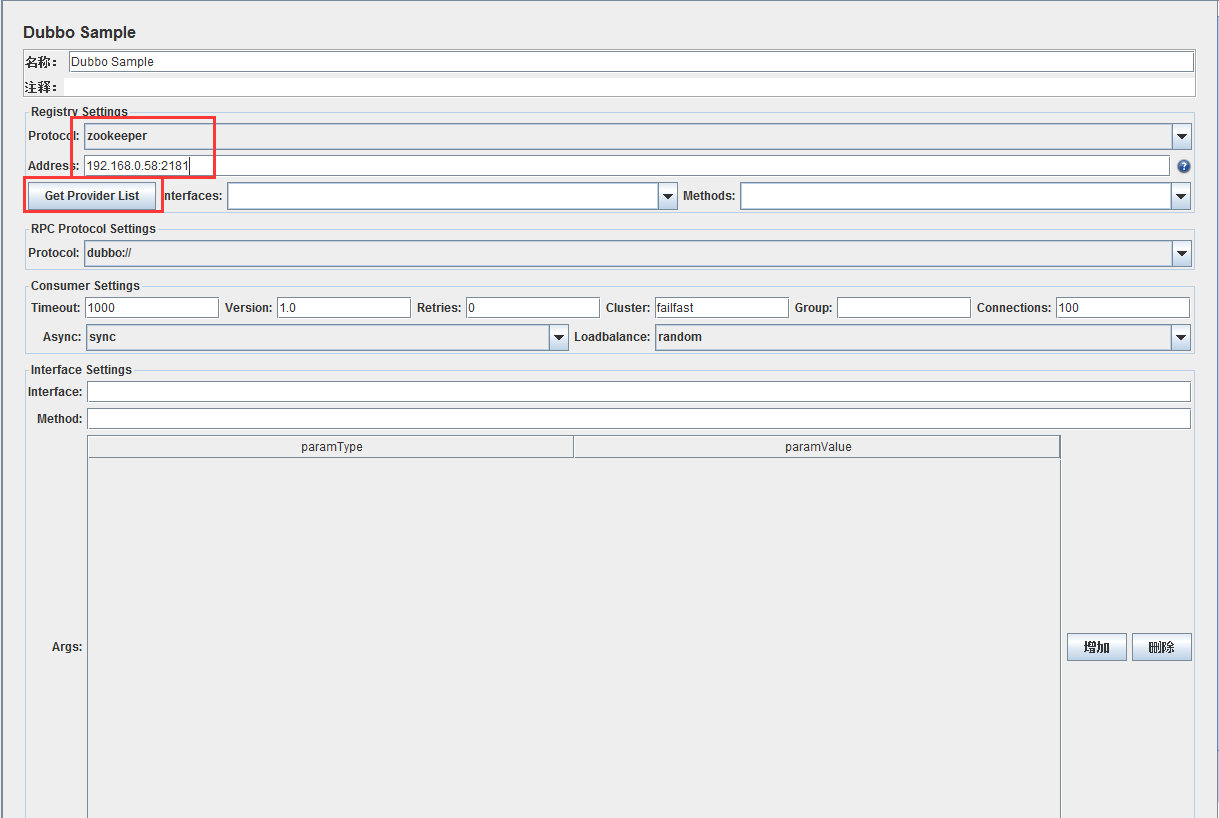
一、中心化的工作流
中心化的工作流又叫做SVN-style,适用于熟悉svn的管理流程来过渡到git(分布式版本控制系统),如果你的开发团队成员已经很熟悉svn,集中式工作流让你无需去适应一个全新流程就可以体验Git带来的收益。这个工作流也可以作为向更Git风格工作流迁移的友好过渡,入下图所示:
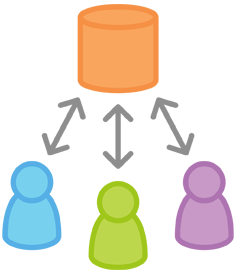
像SVN一样,集中式工作流以中央仓库作为项目所有修改的单点实体。相比SVN缺省的开发分支trunk,Git叫做master,所有修改提交到这个分支上。该工作流只用到master这一个分支。
开发者开始先克隆中央仓库。在自己的项目拷贝中,像SVN一样的编辑文件和提交修改;但修改是存在本地的,和中央仓库是完全隔离的。开发者可以把和上游的同步延后到一个方便时间点。
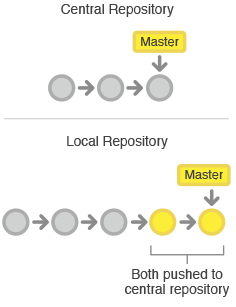
要发布修改到正式项目中时,开发者要把本地master分支的修改『推(push)』到中央仓库中。这相当于svn commit操作,但push操作会把所有还不在中央仓库的本地提交都推上去,下图所示:
为什么会有冲突,冲突的原因
使用svn-style的方式避免不了会遇到冲突,冲突的解决尤为重要,中央仓库代表了正式项目(git里是master,svn里是trunk),所以提交历史应该被尊重且是稳定不变的。如果开发者本地的提交历史和中央仓库有分歧,Git会拒绝push提交否则会覆盖已经在中央库的正式提交。
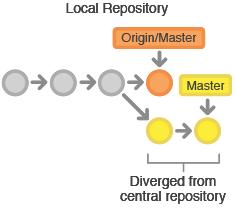
在开发者提交自己功能修改到中央库前,需要先fetch在中央库的新增提交,rebase自己提交到中央库提交历史之上。这样做的意思是在说,我要把自己的修改加到别人已经完成的修改上,最终的结果是一个完美的线性历史,就像以前的SVN的工作流中一样。如果本地修改和上游提交有冲突,Git会暂停rebase过程,给你手动解决冲突的机会。
举例说明
让我们举一个例子来理解一下中心化工作流-svn-style
比如说:wms项目组有两个开发人员:小明、小健,看他们是如何开发自己的功能并提交到中央仓库上的。
第一步:小明、小健从中央仓库克隆代码
git clone http://gitlab.xxx.com/demo/gitflow-demo.git
ps.克隆仓库时Git会自动添加远程别名origin指向中央仓库,不动请参考:git clone --help
克隆代码入下图示例:
小明开发新功能:
小明使用标准的Git过程开发功能:编辑、暂存(Stage)和提交,这里注意不进行push操作,只做本地commit提交到本地仓库
git status # 查看本地仓库的修改状态
git add # 暂存文件
git commit # 提交文件
这些操作都是本地的提交操作,小明可以反复的按照需求来进行代码修改,不需要担心中央仓库的改变和小健自己本地的改变。
小明开发功能都在本地上进行就如下图示例:
小健开发新功能
小健也是一样使用标准的Git过程开发功能,编辑、暂存、提交,他和小明一样不需要关系中央仓库的改变和小明自己本地的改变,所有的提交都是私有的,都是在自己的本地仓库中。
小健开发功能都在本地上进行就如下图所示:
小明开发好了功能想发布了
小明把他的本地仓库修改的代码push到中央仓库,使用下面命令
git push origin master
ps. origin是在小明克隆仓库时Git创建的远程中央仓库别名。master参数告诉Git推送的分支
ps. 我们这里假设团队中只有两个人(小明、小健),由于中央仓库自从小明克隆以来还没有被更新过,所以push操作不会有冲突,成功完成。
小明把他自己的本地代码push到中央仓库就如下图所示:
小健开发好了功能也想发布了
小健也是使用git push命令来推送自己本地仓库的改动到中央仓库,使用下面命令
git push origin master
但是此时origin已经由于小明在之前推送了小明本地的代码上去,因此已经和小健本地的代码产生了分歧,推送会被拒绝,入下图所示:
拒绝的信息如下:
$ git push origin master
To http://gitlab.xxx.com/demo/gitflow-demo.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'http://gitlab.xxx.com/demo/gitflow-demo.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
遇到这种问题我们该怎么解决了?
小健可以使用pull操作合并上游的修改到自己的仓库中,git的pull操作类似于svn的update操作,拉取所有上游小明提交命令到小健的本地仓库,但是要加上–rebase参数,例如下面命令:
git pull --rebase origin master
这里特别解释一下上面命令的实际操作原理
–rebase选项告诉git把小健的提交移到(同步了中央仓库修改后的master分支)的顶部(head),也就是说它会先把小健本地分支的本地提交先移除掉,移动到一旁,然后把小健的本地分支同步中央仓库的最新版本(小明提交的记录),然后把刚刚移除了(小健本地的修改)再提交回小健的本地分支(已同步了最新中央仓库的代码,也就是说小明的代码)。
不加rebase的话git会在xiaoming和xiaojian的提交后再进行一次merge操作从而就会多了一个merge的提交记录,加了rebase的话xiaojian的提交已经包含了与xiaoming代码的冲突,因此不会多一个merge操作。
rebase(没有冲突)操作的过程例如下图所示:
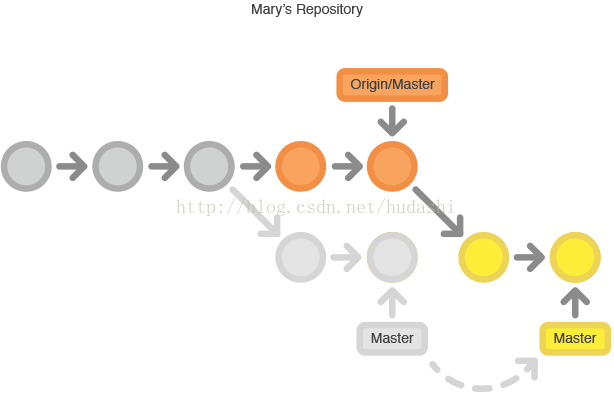
rebase(存在冲突)操作的过程例如下图所示:
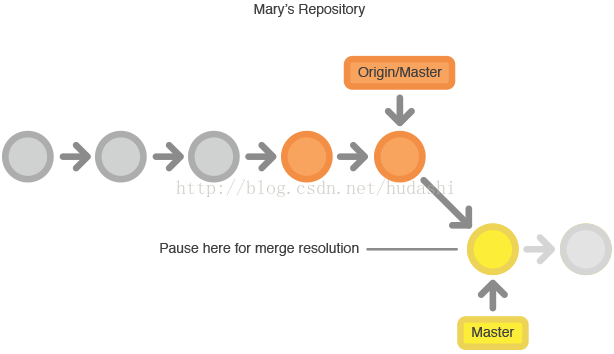
ps. git会暂定rebase操作直到你去解决了冲突之后执行git rebase --continue来继续进行操作.
rebase实操记录
下面是rebase的操作实践,xiaojian执行git pull --rebase origin master,比如说xiaoming和xiaojian冲突到了同一个文件上会显示出下面的信息,例如:
$ git pull --rebase origin master
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From http://gitlab.xxx.com/demo/gitflow-demo
* branch master -> FETCH_HEAD
788c7f3..9c7c9d2 master -> origin/master
First, rewinding head to replay your work on top of it...
Applying: xiaojian 提交
error: Failed to merge in the changes.
Using index info to reconstruct a base tree...
M README.md
Falling back to patching base and 3-way merge...
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Patch failed at 0001 xiaojian 提交
The copy of the patch that failed is found in: .git/rebase-apply/patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
如果装了小乌龟或者sourcetree目录下文件会显示冲突警告图标
根据上面的警告我们需要手动的解决冲突,解决完冲突使用git add/rm <conflicted_files>命令标记解决冲突完毕,再执行git rebase --continue继续下一步操作。
ps. 如果这个时候后悔执行了git pull --rebase origin master想撤销怎么办?可以执行git rebase --abort撤销rebase操作。
接下来是xiaojian执行push到中央仓库并且解决冲突的脚本记录如下:
手动解决冲突
$ git add README.md
$ git rebase --continue
Applying: xiaojian 提交
$ git push origin master
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 305 bytes | 305.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0)
To http://gitlab.xxx.com/demo/gitflow-demo.git
9c7c9d2..87aed2d master -> master
然后我们去gitlab上看我们的提交记录是个什么样子的,例如下图:
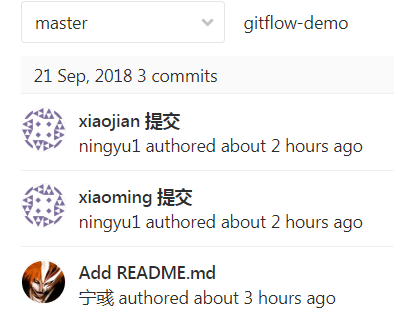

ps.提交记录非常的清晰明了而且是按照push仓库的顺序来显示的提交记录,这个样子也是我们希望看到的。
但是往往并没有这么顺利,理想很好现实确实各种问题。
比如说git pull的时候忘记添加--rebase参数了怎么办?
如果忘加了--rebase这个选项,pull操作仍然可以完成,但每次pull操作在同步中央仓库中别人的修改时,需要提交合并代码的记录从而导致提交历史中会多一个『合并提交』的记录。
例如下面所示:
$ git pull origin master
From http://gitlab.xxx.com/demo/gitflow-demo
* branch master -> FETCH_HEAD
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
手动解决完冲突
$ git add .
$ git commit -m "合并冲突"
[master 9fab0c8] 合并冲突
$ git push origin master
Counting objects: 6, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (6/6), 581 bytes | 290.00 KiB/s, done.
Total 6 (delta 2), reused 0 (delta 0)
To http://gitlab.xxx.com/demo/gitflow-demo.git
f862f27..9fab0c8 master -> master
然后我们去gitlab上看我们的提交记录是个什么样子的,例如下图:
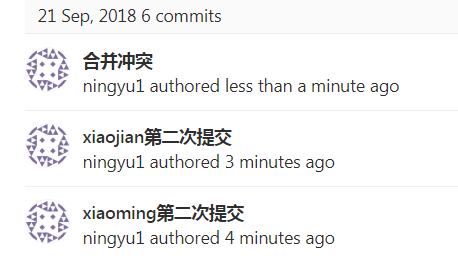

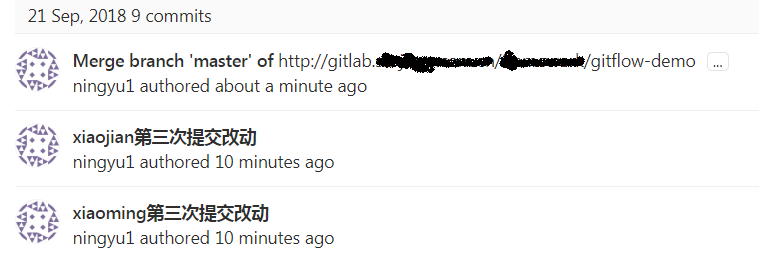
ps. 会多出一个合并的提交,而且查看tree型图会发现不是一个线性的轨迹
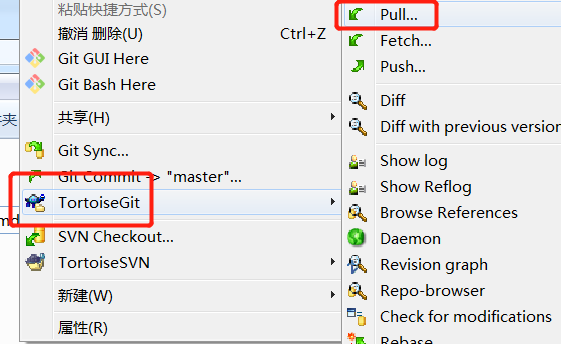
如果使用的是小乌龟sourcetree这种工具合并冲突会是什么样子?让我们演示一下:
首先
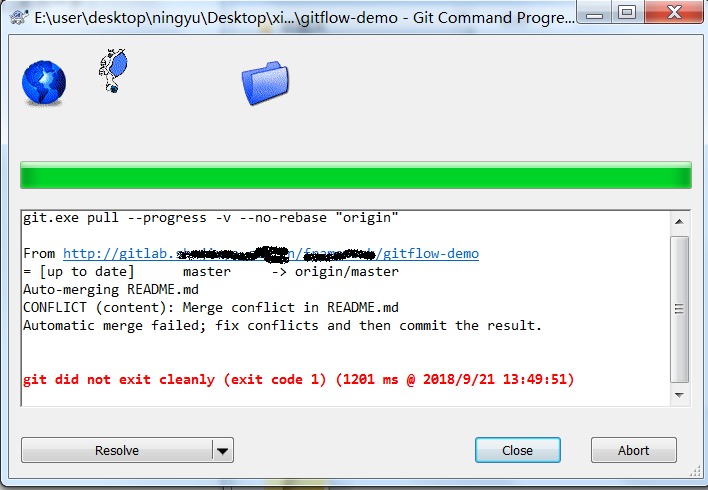
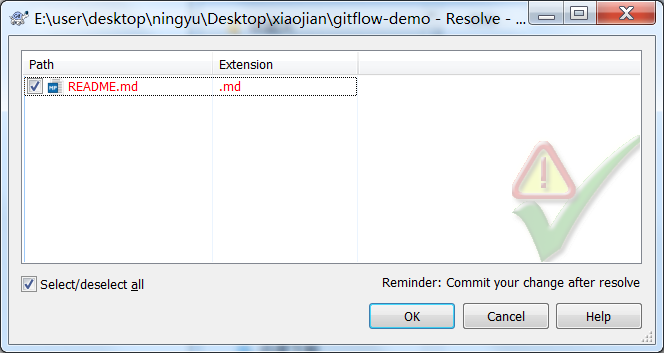
手动解决完冲突,选择标记为已经解决
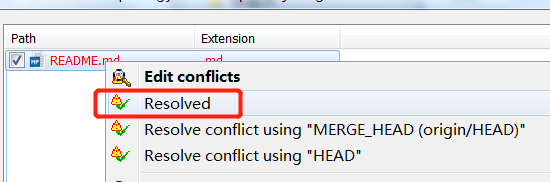
我们需要把解决的冲突提交上去
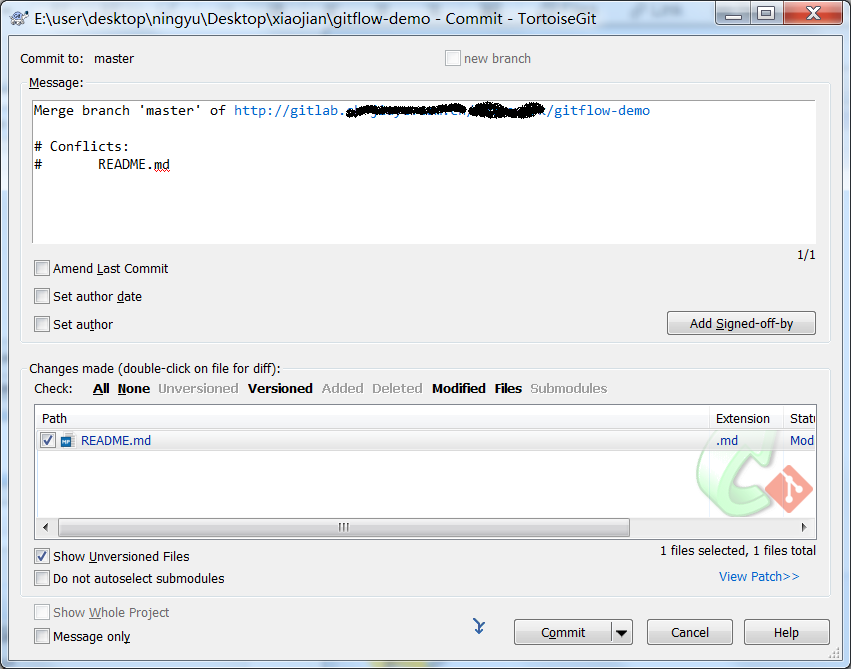
自动生成的comment是Merge branchmasterxxxxxxx
提交完成后右键菜单选择git push
这个时候我们去gitlab上看我们的提交记录是个什么样子的,例如下图:

示例总结以及注意事项
所以我们建议对于集中式工作流,最好是使用rebase,而不是使用merge生成一个合并提交