问题发生在
utf8字符集信息
Symbol information table
|Name: |Utf-8 Character|
|:–:|:–:|
|Unicode Subset:|CJK Extension B|
|Unicode HEX:|U+20046|
|ASCII value:|131142|
|HTML:|𠁆|
|CSS:|\20046|
它属于utf8的字符集,具体可参考:传送门
既然属于utf8的字符集那为什么数据库保存这个字会出现非法字符的错误呢?错误如下:
### Cause: java.sql.SQLException: Incorrect string value: '\xF0\xA5\x8A\x8D' for column 'DESCRIPTION' at row 1 |
让我们先了解一下utf8的编码,UTF-8编码是U+2528D,属于CJK Unified Ideographs Extension B(中日韩统一表意文字扩充B)字符集的字符,处于第二辅助平面(SIP,表意文字补充平面),不属于我们通常所见的基本多文种平面(BMP,即Unicode编码范围在0000-FFFF之内)的字符。保存一个字;相比之下,在BMP范围之内的字符只需要占用3 Bytes。仅仅就因为字符保存位数不同,就让程序开发出现了难题。
来自wikipedia的Unicode字符平面映射
目前的Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536(即216)个代码点。然而目前只用了少数平面。
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面 | (未正式使用[1]) Tertiary Ideographic Plane,简称TIP |
| 4号平面 至 13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区)[2] | Private Use Area-A,简称PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区)[2] | Private Use Area-B,简称PUA-B |
具体可查看:传送门
究其原因就是这个字保存需要占4 Bytes的字节,mysql在MySQL 5.6+版本之后支持4Bytes字节(utf8mb4)的存储,首先先看一下mysql编码如何设置?
数据库字符集设置
建库语句中需要指定字符集编码为:utf8mb4
建库语句中需要指定字符集校对规则为:utf8mb4_general_ci
建表语句中需要指定字符集编码为:utf8mb4
表字段需要指定字符集编码为:utf8mb4
表字段collation需要指定字符集校验规则:utf8mb4_general_ci
如下图:

CREATE TABLE `t_application` ( |
utf8mb4不生效问题分析
完成上面的字符集设置之后我们使用程序保存
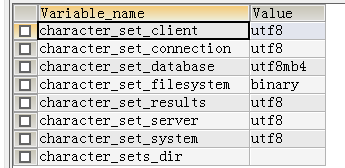
让我们来看回数据库charset设置,SHOW VARIABLES LIKE 'CHARACTER%',关注character_set_server这个字符设置
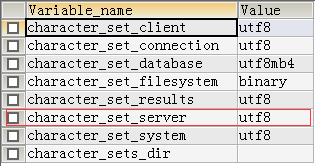
character_set_server在默认情况下为latin1
/* |
按照上面的说法,如果character_set_server和character_set_database变量的值不同,则新建数据库的字符集以character_set_server为准,而不是按照character_set_database。
我的理解是character_set_database指定了utf8mb4后目标库应该按照设置的字符集格式走才对,只有没有设置的库才会走默认的,但是现在测试下来,character_set_server必须修改为utf8mb4,否则保存这种字符依然提示非法字符集,不太清楚具体什么原因。
如果数据库按照上面设置了以后还是无法保存的话,应该就是mysql驱动的问题和数据库连接串字符集的问题。下面让我们看一下从mysql server到mysql驱动到数据源再到应用所有的utf8mb4设置。
完整的正确设置
Mysql服务端配置
建库语句中需要指定字符集编码为:utf8mb4
建库语句中需要指定字符集校对规则为:utf8mb4_general_ci
建表语句中需要指定字符集编码为:utf8mb4
表字段需要指定字符集编码为:utf8mb4
表字段collation需要指定字符集校验规则:utf8mb4_general_ci
mysql ini配置文件指定character_set_server
[client] |
ps. character_set_server设置成utf8或使用默认latin1,在直接使用sql插入特殊字符和emoji表情时数据库显示?????乱码,使用程序(mybatis)插入特殊字符和emoji表情时报错:java.sql.SQLException: Incorrect string value: ‘\xF0\xA5\x8A\x8D’ for column ‘某某列’ at row 1
java连接mysql驱动版本
mysql-connector-java版本在5.1.13+才支持utf8mb4,因此在选用连接驱动时应注意这个问题,我们使用的驱动是mysql-connector-java-5.1.41。
数据源配置
我们使用的druid数据源配置上需要加上connectionInitSqls属性配置,具体如下:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" |
ps.但是我实际测试下来,这个参数不加也没有什么问题,可以正常保存这种特殊字符和emoji表情,官方建议配置。
数据库连接串配置
我们的配置如下:
jdbc.url=jdbc:mysql://ip:port/databaseName?useUnicode=true&characterEncoding=UTF-8&noAccessToProcedureBodies=true&autoReconnect=true |
建议去掉useUnicode和characterEncoding的配置,使用如下配置:
jdbc.url=jdbc:mysql://ip:port/databaseName?noAccessToProcedureBodies=true&autoReconnect=true |
ps.但是我实际测试下来,连接串上增加useUnicode=true&characterEncoding=utf8也没有什么问题,可以正常保存这种特殊字符和emoji表情。
总结
最主要的是mysql服务端的character_set_server需要和character_set_database保持一致修改为utf8mb4,因此我们先不考虑数据库连接串和druid数据源配置修改,但是mysql-connector-java版本必须使用5.1.13+


