最近在参考CQRS DDD架构来进行公司的库存中心重构设计,在CQRS架构中需要一个in-memory的方式快速修改库存在通过消息驱动异步更新到DB,也就是说内存的数据是最新的,DB的数据是异步持久化的,在某一个时刻内存和DB的数据是存在不一致的,但是满足最终一致性。
这样我们就需要内存当作前置DB在使用,因此不单纯的只满足修改数据,还需要满足Query的要求,内存结构的数据Query是比较麻烦的,它不像DB那样已经实现好了索引检索,需要我们自己来设计Key的机构和搜索索引的构建。
当然行业里也有这样的做法,对数据修改的时候双写到内存(Redis)和ElasticSearch再异步到DB,这样Query全部走向ElasticSearch,但是我觉得这样做的复杂度会增加很多,所以就在看如何基于Redis来设计一个搜索引擎。
看到了RedisLabs团队开发的基于Redis的搜索引擎:RediSearch
RediSearch
官方给出的描述
Redisearch implements a search engine on top of redis, but unlike other redis search libraries, it does not use internal data structures like sorted sets. |
主要特点
高性能的全文搜索引擎(Faster, in-memory, highly available full text search),可作为Redis Module运行在Redis上。但是它与其他Redis搜索库不同的是,它不使用Redis内部数据结构,例如:集合、排序集(ps.后面会写一篇基于Redis的数据结构来设计搜索引擎),Redis原声的搜索还是有很大的局限性,简单的分词搜索是可以满足,但是应用到复杂的场景就不太适合。
- Full-Text indexing of multiple fields in documents.
- Incremental indexing without performance loss.
- Document ranking (provided manually by the user at index time).
- Field weights.
- Complex boolean queries with AND, OR, NOT operators between sub-queries.
- Prefix matching in full-text queries.
- Auto-complete suggestions (with fuzzy prefix suggestions)
- Exact Phrase Search.
- Stemming based query expansion in many languages (using Snowball).
- Support for logographic (Chinese, etc.) tokenization and querying (using Friso)
- Limiting searches to specific document fields (up to 128 fields supported).
- Numeric filters and ranges.
- Geographical search utilizing redis’ own GEO commands.
- Supports any utf-8 encoded text.
- Retrieve full document content or just ids.
- Automatically index existing HASH keys as documents.
- Document Deletion (Update can be done by deletion and then re-insertion).
- Sortable properties (i.e. sorting users by age or name).
下面是中文版本
- 多个字段的文档的全文索引。
- 没有性能损失增量索引。
- 文档排名(由用户提供手动指数时间)。
- 字段权重。
- 在子查询之间使用AND,OR,NOT运算符进行复杂的布尔查询。
- 前缀匹配全文查询。
- 自动完成建议以模糊前缀(建议)
- 准确短语搜索。
- 阻止基于查询扩展多种语言(使用Snowball)。
- 支持语标的(中国等)标记和查询(使用Friso)
- 将搜索限制在特定的文档字段(128字段支持)。
- 数字过滤器和范围。
- 利用redis自己的GEO命令进行地理搜索。
- 支持任何utf-8编码的文本。
- 获取完整的文档内容或者只是id。
- 自动索引现有HASH keys文件。
- 文档删除(更新可以通过删除然后re-insertion)。
- 可排序属性(即按年龄或名称对用户进行排序)。
集群
当然还支持分布式集群,只不过集群还是试验阶段还不建议正式应用到企业级应用上。
暂不支持
- Spelling correction(拼写更正)
- Aggregations(集合)
支持的Client类库
Official (Redis Labs) and community Clients:
| Language | Library | Author | License | Comments |
|---|---|---|---|---|
| Python | redisearch-py | Redis Labs | BSD | Usually the most up-to-date client library |
| Java | JRediSearch | Redis Labs | BSD | - |
| Go | redisearch-go | Redis Labs | BSD | Incomplete API |
| JavaScript | RedRediSearch | Kyle J. Davis | MIT | Partial API, compatible with Reds |
| C# | NRediSearch | Marc Gravell | MIT | Part of StackExchange.Redis |
| PHP | redisearch-php | Ethan Hann | MIT | - |
| Ruby on Rails | redi_search_rails | Dmitry Polyakovsky | MIT | - |
| Ruby | redisearch-rb | Victor Ruiz | MIT | - |
类库支持的还算丰富,可以尝试使用一下。
性能
性能对比是以ElasticSearch、Solr来进行对比,官方的benchmark数据,benchmark程序地址
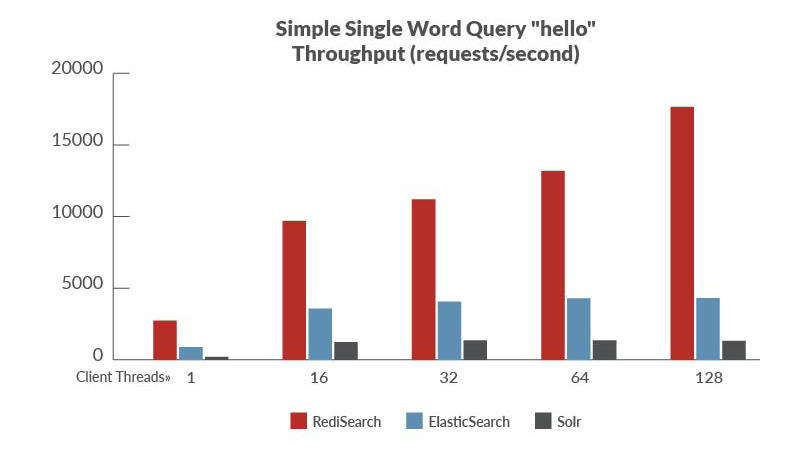
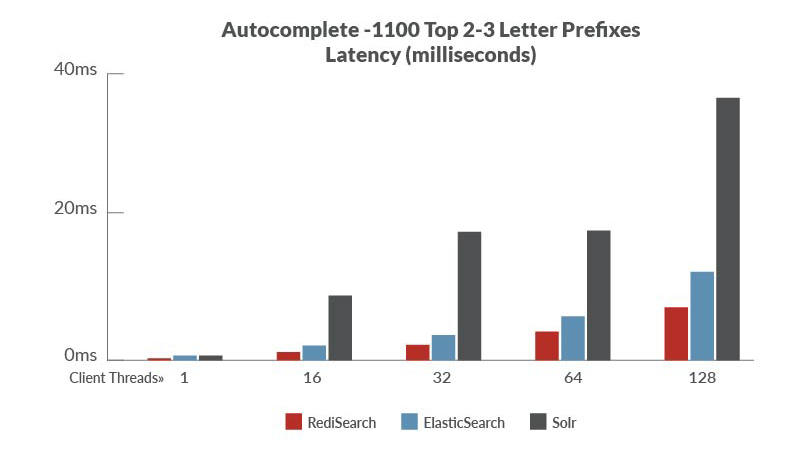
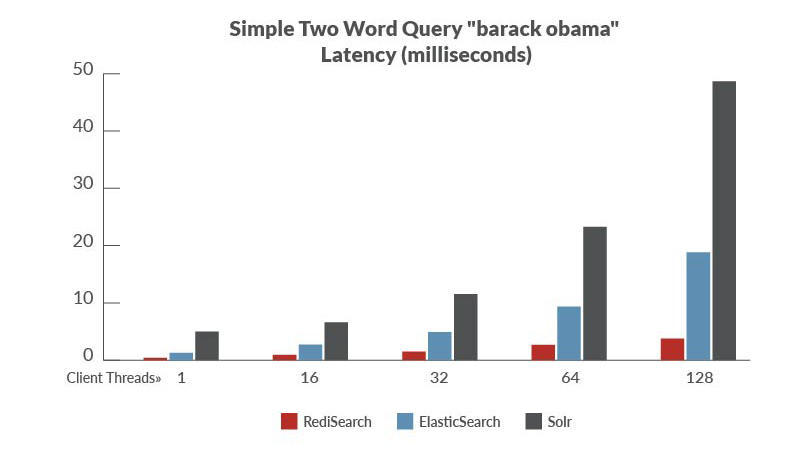
总结:
从数据上看,使用RediSearch的吞吐量高、延迟低,但是相比于ElasticSearch和Solr支持的特性上还有些欠缺比如:中文的模糊搜索支持的不是很好,但是其性能很高在某些场景是可以作为搜索引擎的替代方案来试用。
案例资料:
上述就是关于RediSearch的资料整理,后面会尝试使用它来构建搜索引擎,会记录使用过程经历。


