
TiDB使用笔记 —— 测试环境集群部署
TiDB是一个NewSql的分布式数据库,具体介绍我们引用官方的简介
简介
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 NewSQL 数据库。
TiDB 具备如下 NewSQL 核心特性:
SQL支持(TiDB 是 MySQL 兼容的) 水平弹性扩展(吞吐可线性扩展) 分布式事务 跨数据中心数据强一致性保证 故障自恢复的高可用 海量数据高并发实时写入与实时查询(HTAP 混合负载) TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
我们来看一下TiDB的架构图
架构图
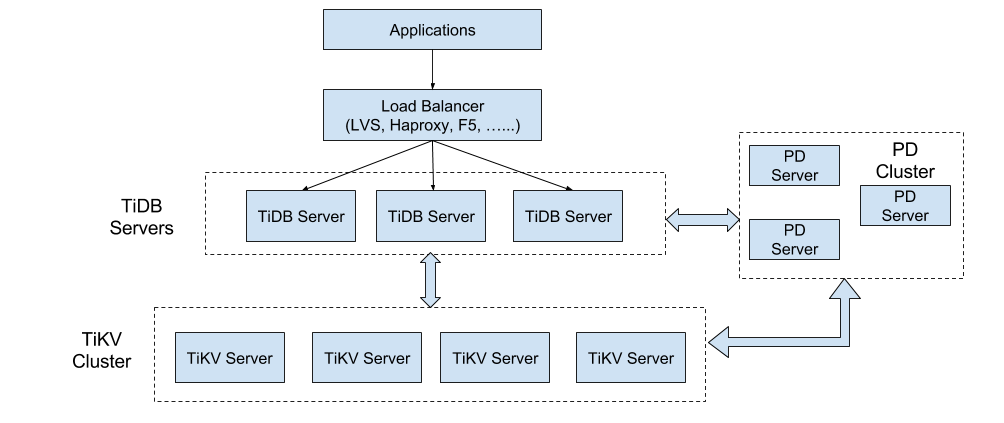
从架构图中可以看出TiDB的三大组件都支持水平扩展而且内部通信使用的是gRPC,关于TiDB和gRPC的那些事可以查看InfoQ的文章:《TiDB与gRPC的那点事》
TiDB使用的TiKV作为存储,官方建议至少TiKV使用ssd硬盘,如果条件好pd模块最好也使用ssd硬盘。
下来我们具体看一下三大组件分别都是干什么的
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
特性
可以无限水平扩展而且三大组件都是高可用,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。关于三大组件出现问题后如何恢复可以查看:《tidb-整体架构中的高可用章节》
官方的部署建议
TiDB使用的TiKV作为存储,官方建议至少TiKV使用ssd硬盘,如果条件好pd模块最好也使用ssd硬盘。
建议 4 台及以上,TiKV 至少 3 实例,且与 TiDB、PD 模块不位于同一主机。
| 组件 | CPU | 内存 | 本地存储 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 8核+ | 16 GB+ | SAS, 200 GB+ | 千兆网卡 | 1(可与 PD 同机器) |
| PD | 8核+ | 16 GB+ | SAS, 200 GB+ | 千兆网卡 | 1(可与 TiDB 同机器) |
| TiKV | 8核+ | 32 GB+ | SSD, 200 GB+ | 千兆网卡 | 3 |
| - | - | - | - | 服务器总计 | 4 |
个人觉得这个使用的成本还是蛮高的。具体可以看《软、硬件环境要求》
测试部署
TiDB的部署方式还是蛮丰富的,可以使用Ansible在线以及离线的部署集群,TiDB-Ansible 是 PingCAP 基于 Ansible playbook 功能编写的集群部署工具。使用 TiDB-Ansible 可以快速部署一个完整的 TiDB 集群(包括 PD、TiDB、TiKV 和集群监控模块)。
TiDB同时也支持Docker部署方案,由于我们公司内网使用docker容器的方式管理所有服务,所以我这里使用docker方式部署。
我们使用Rancher来做企业级的容器管理平台,没有使用k8s、mesos来进行编排管理,使用的是Rancher自带的Cattle,Cattle不光有编排管理还包含了应用、服务、卷、负载均衡、健康检查、服务升级、dns服务、等功能,有兴趣的可以查看:《Rancher官方文档-Cattle》
在进行部署之前需要先去Docker官方镜像库中拉TiDB集群所需要的三大组件的镜像: Docker 官方镜像仓库
docker pull pingcap/tidb:latest
docker pull pingcap/tikv:latest
docker pull pingcap/pd:latest
这三个组件的镜像都不大,TiKV只有54MB,PD只有21MB,TiDB只有17MB
这个我需要说一下他们这块做的还是很不错的,将镜像压缩的都比较小,去除了很多无用的东西。
我们需要创建7个容器来部署一个TiDB集群:
| 容器 | 容器IP | 宿主机IP | 部署服务 | 数据盘挂载 |
|---|---|---|---|---|
| PD1 | 10.42.59.28 | 192.168.18.108 | PD1 | /home/docker/TiDB |
| PD2 | 10.42.202.152 | 192.168.18.108 | PD2 | /home/docker/TiDB |
| PD3 | 10.42.214.245 | 192.168.18.108 | PD3 | /home/docker/TiDB |
| TiDB | 10.42.188.35 | 192.168.18.109 | TiDB | /home/docker/TiDB |
| TiKV1 | 10.42.106.167 | 192.168.18.109 | TiKV1 | /home/docker/TiDB |
| TiKV2 | 10.42.34.97 | 192.168.18.109 | TiKV2 | /home/docker/TiDB |
| TiKV3 | 10.42.170.152 | 192.168.18.109 | TiKV3 | /home/docker/TiDB |
用docker的好处就是资源可以压缩到最小,我6个容器可以放在一到两台虚机上
查看pd集群信息
http://192.168.18.108:2379/v2/members
http://192.168.18.108:2479/v2/members
http://192.168.18.108:2579/v2/members
返回信息以json格式,三台pd返回集群信息都是一样的
{"members":[{"id":"969b7171b723b804","name":"pd3","peerURLs":["http://192.168.18.108:2580"],"clientURLs":["http://192.168.18.108:2579"]},{"id":"d141f07798663b47","name":"pd2","peerURLs":["http://192.168.18.108:2480"],"clientURLs":["http://192.168.18.108:2479"]},{"id":"e5e987f33a60e672","name":"pd1","peerURLs":["http://192.168.18.108:2380"],"clientURLs":["http://192.168.18.108:2379"]}]}
具体的docker容器创建命令可以参考官方文档:《Docker部署方案》
TiDB支持mysql协议可以使用任意mysql客户端连接,默认安装好的集群使用mysql登录,端口:4000,用户名:root,密码为空,修改密码跟mysql修改密码方式完全一样。
SET PASSWORD FOR 'root'@'%' = 'xxx';
下面说几个我们必须要关心的东西。
事务隔离级别可以查看:《TiDB 事务隔离级别》
SQL语法没有什么变化,具体可以查看:《SQL语句语法》
SQL执行计划什么的都有跟使用mysql几乎一样,还增加了json的支持,可以设置字段列存储类型为json格式。
具体与MySQL有什么差异可以查看:《与MySQL兼容性对比》
历史数据回溯问题可以查看:《TiDB 历史数据回溯》
Binlog可以使用:《TiDB-Binlog 部署方案》
好了今天的大致介绍和测试环境集群搭建都到这里,后面会总结使用中遇到的问题。
