Cache设计和使用上的套路
一、管道(pipeline)提升效率
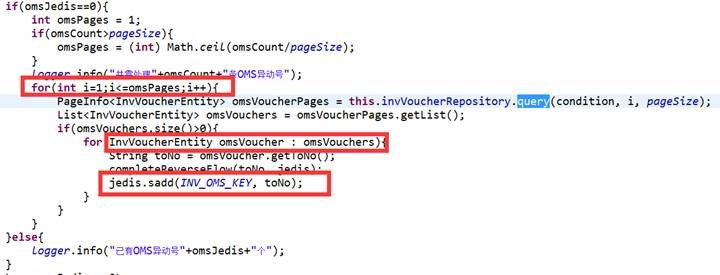
Redis是一个cs模式的tcp server,使用和http类似的请求响应协议。一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。每执行一个命令需要2个tcp报文才能完成,由于通信会有网络延迟,假如从client和server之间的包传输时间需要0.125秒,那么执行四个命令8个报文至少会需要1秒才能完成,这样即使redis每秒能处理100k命令,而我们的client也只能一秒钟发出四个命令。这显示没有充分利用 redis的处理能力。因此我们需要使用管道(pipeline)的方式从client打包多条命令一起发出,不需要等待单条命令的响应返回,而redis服务端会处理完多条命令后会将多条命令的处理结果打包到一起返回给客户端(它能够让(多条)执行命令简单的,更加快速的发送给服务器,但是没有任何原子性的保证)官方资料
【反例】
 【正例】
【正例】
//管道,批量发送多条命令,但是不支持namespace需要手动添加namespace
Pipeline pipelined = redisClient.pipelined();
pipelined.set(key, value);
pipelined.get(key);
pipelined.syncAndReturnAll(); //发送命令并接受返回值
pipelined.sync();//发送命令不接受返回值
使用管道注意事项: 1. tcp报文过长会被拆分。 2. 如果使用pipeline服务器会被迫使用内存队列来发送应答(服务器会在处理完命令前先缓存所有的命令处理结果) 3. 打包的命令越多,缓存消耗内存也越多,所以并不是打包命令越多越好,需要结合测试找到合适我们业务场景的量(双刃剑) 4. 不保证原子性,因此在Redis中没有数据需要走DB获取数据,Redis也支持事务(multi、watch)但是会影响性能(没有事务和有事务相差还是蛮大的),不是非要强一致的场景请不要使用。
二、连接池使用问题
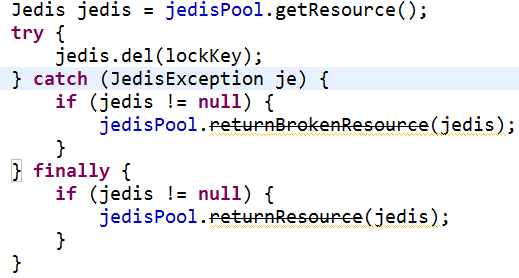
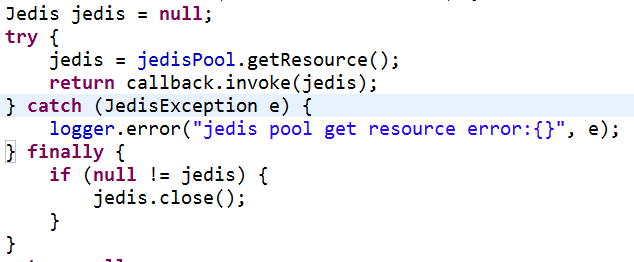
jedis客户端2.4版本以上对连接池资源使用上进行了优化,提供了更优雅的资源回收方法并且支持broken处理,提供close方法替换原来的回收资源方法(returnBrokenResource 、returnResource)
【反例】
 【正例】
【正例】
三、使用key值前缀来作命名空间
虽然说Redis支持多个数据库(默认32个,可以配置更多),但是除了默认的0号库以外,其它的都需要通过一个额外请求才能使用。所以用前缀作为命名空间可能会更明智一点。另外,在使用前缀作为命名空间区隔不同key的时候,最好在程序中使用全局配置来实现,直接在代码里写前缀的做法要严格避免,这样可维护性实在太差了。
命名分割符使用 “.” 分隔
【正例】
四、expire对于key过期时间来控制垃圾回收
Redis是一个提供持久化功能的内存数据库,如果你不指定上面值的过期时间(TTL),并且也不进行定期的清理工作,那么你的Redis内存占用会越来越大,当有一天它超过了系统可用内存,那么swap上场,离性能陡降的时间就不远了。所以在Redis中保存数据时,一定要预先考虑好数据的生命周期,这有很多方法可以实现。
比如你可以采用Redis自带的过期时间(setEX)为你的数据设定过期时间。但是自动过期有一个问题,很有可能导致你还有大量内存可用时,就让key过期去释放内存,或者是内存已经不足了key还没有过期。
(LRU)如果你想更精准的控制你的数据过期,你可以用一个ZSET来维护你的数据更新程度,你可以用时间戳作为score值,每次更新操作时更新一下score,这样你就得到了一个按更新时间排序序列串,你可以轻松地找到最老的数据,并且从最老的数据开始进行删除,一直删除到你的空间足够为止。
【正例】
redisClient.setex(bizkey, 60, value);//set一个key并设置ttl60秒
五、乱用(不要有个锤子看哪都是钉子)
当你使用Redis构建你的服务的时候,一定要记住,你只是找了一个合适的工具来实现你需要的功能。而不是说你在用Redis构建一个服务,这是很不同的,你把Redis当作你很多工具中的一个,只在合适使用的时候再使用它,在不合适的时候选择其它的方法。
我们对它的定位更多是Cache服务而非DB
六、缓存设计的误区
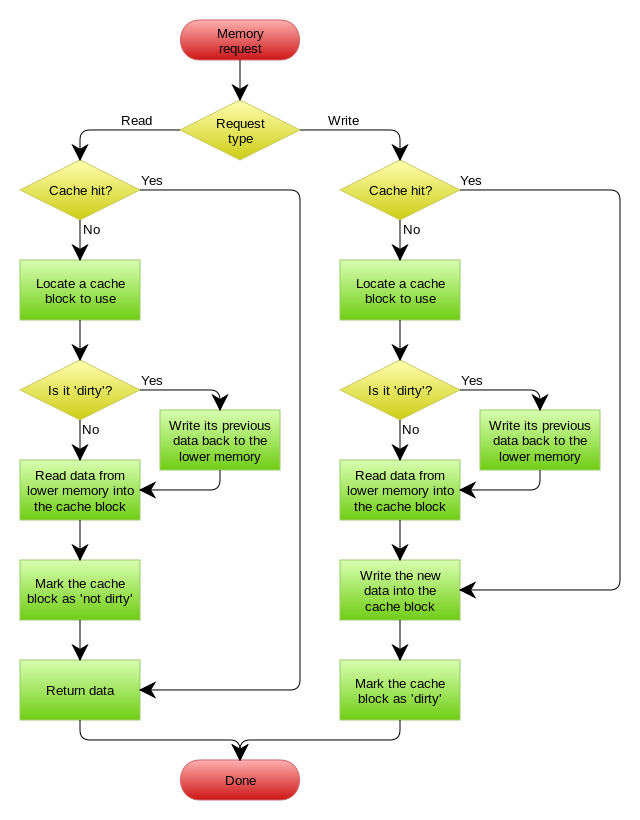
我们通常是这样设计的,应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
那试想一下,如果取出来的null,需不需要放入cache呢?答案当然是需要的。
我们试想一下如果取出为null不放入cache会有什么结果?很显然每次取cache没有走db返回null,很容易让攻击者利用这个漏洞搞垮你的服务器,利用洪水攻击让你的程序夯在这个地方导致你的正常流程抢不到资源。
七、缓存更新的问题
以下内容摘自酷壳-COOLSHELL的文章《缓存更新的套路》
很多人在写更新缓存数据代码时,先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。然而,这个是逻辑是错误的。试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
正确更新缓存的Design Pattern有四种:Cache aside, Read through, Write through, Write behind caching
Cache Aside Pattern
这是最常用最常用的pattern了。其具体逻辑如下:
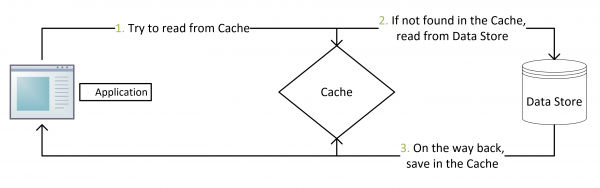
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
Read/Write Through Pattern
我们可以看到,在上面的Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
下图自来Wikipedia的Cache词条。其中的Memory你可以理解为就是我们例子里的数据库。
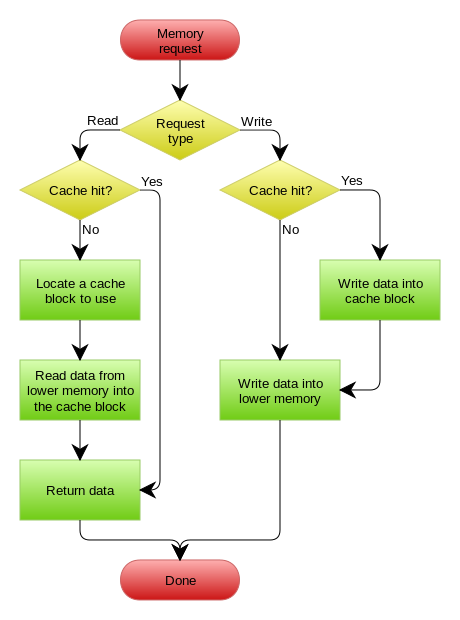 Write Behind Caching Pattern
Write Behind Caching Pattern
Write Behind 又叫 Write Back。一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在wikipedia上有一张write back的流程图,基本逻辑如下: