
Nginx 502 Bad Gateway问题分析与踩过的坑
我相信使用Nginx的都会遇到过502 504 这种bad gateway错误,下面我把碰到这个问题分析过程记录并分享出来。
先让我们看一下具体的错误信息
502 Bad Gateway
The proxy server received an invalid response from an upstream server
从字面上的意思理解,nginx从upstream没有接受到信息,第一感觉就是连接被close?还是超时了?超时的话一般错误信息是 timeout
下面是尝试解决这个问题尝试过的手段
1. 第一感觉是proxy返回超时,因此查找nginx官方文档,找到关于proxy的timeout设置
Syntax: proxy_connect_timeout time;
Default:
proxy_connect_timeout 60s;
Context: http, server, location
Defines a timeout for establishing a connection with a proxied server. It should be noted that this timeout cannot usually exceed 75 seconds.
ps. 这个时间不能超过75秒
Syntax: proxy_read_timeout time;
Default:
proxy_read_timeout 60s;
Context: http, server, location
Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
ps. 两次read的超时时间,并不是整个的response的超时时间
Syntax: proxy_send_timeout time;
Default:
proxy_send_timeout 60s;
Context: http, server, location
Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
ps. 两次write的超时时间,并不是整个request的超时时间
配置后重启nginx服务进行测试仍然有502错误爆出,继续分析
2. 于是想到了keepalive,分析我们的请求报文头,报文是有keep-alive的头信息
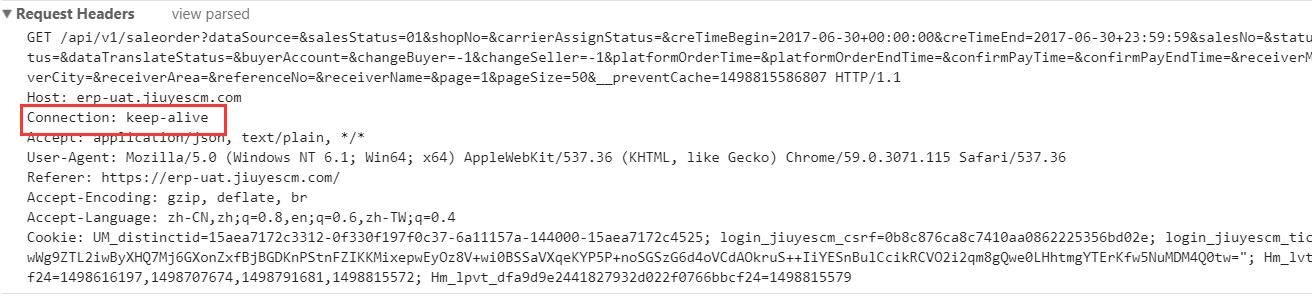 那问题出在哪里?我们应该知道前端请求如果设置为长连接必须要服务端也支持长连接才行,难道是服务器上没有配置长连接导致的?
那问题出在哪里?我们应该知道前端请求如果设置为长连接必须要服务端也支持长连接才行,难道是服务器上没有配置长连接导致的?
翻nginx官网找keepalive的相关配置
Syntax: keepalive_timeout timeout [header_timeout];
Default:
keepalive_timeout 75s;
Context: http, server, location
The first parameter sets a timeout during which a keep-alive client connection will stay open on the server side. The zero value disables keep-alive client connections. The optional second parameter sets a value in the “Keep-Alive: timeout=time” response header field. Two parameters may differ.
The “Keep-Alive: timeout=time” header field is recognized by Mozilla and Konqueror. MSIE closes keep-alive connections by itself in about 60 seconds.
ps.长连接保持的超时时间设置
Syntax: keepalive connections;
Default: —
Context: upstream
This directive appeared in version 1.1.4.
Activates the cache for connections to upstream servers.
The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process. When this number is exceeded, the least recently used connections are closed.
ps. 设置upstream长连接的数量
查看tomcat的keepalive的设置
keepAliveTimeout:表示在下次请求过来之前,tomcat保持该连接多久。这就是说假如客户端不断有请求过来,且为超过过期时间,则该连接将一直保持。
maxKeepAliveRequests:表示该连接最大支持的请求数。超过该请求数的连接也将被关闭(此时就会返回一个Connection: close头给客户端)。
以上设置调整后重启服务进行测试,仍然有502错误爆出,继续分析
3. 在nginx的log中发现了请求都是使用的HTTP 1.0,大家应该知道HTTP 1.0是不支持长连接的,于是顺着这条线继续查下去,为什么请求进来都是HTTP1.0呢?
查看nginx官网的文档,发现proxy是可以只定HTTP版本的
Syntax: proxy_http_version 1.0 | 1.1;
Default:
proxy_http_version 1.0;
Context: http, server, location
This directive appeared in version 1.1.4.
Sets the HTTP protocol version for proxying. By default, version 1.0 is used. Version 1.1 is recommended for use with keepalive connections and NTLM authentication.
ps. 1.1.4以后的版本nginx默认使用的是HTTP1.1
于是我们查看一下nginx的版本 nginx -v,我们用的是nginx version: nginx/1.10.1,理论上默认开启的http1.1,不过没关系我们配置一下proxy_http_version 1.1试一下,这个参数要结合上面说道的upstream中的keepalive一起使用才能有效果。
修改好之后重启服务再次进行测试,依然有502的错误爆出,无解!!!,继续分析,为什么版本不生效呢?
我们前端请求的报文:
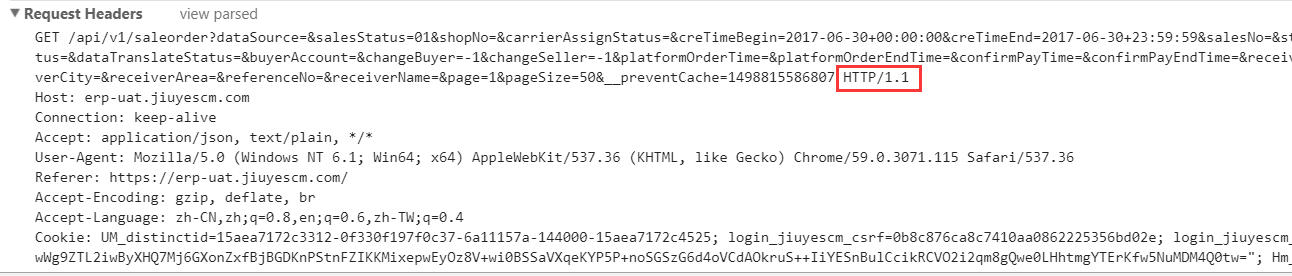 请求的明明是HTTP 1.1为什么到nginx中成了HTTP 1.0?
请求的明明是HTTP 1.1为什么到nginx中成了HTTP 1.0?
于是想到我们使用了阿里云的SLB,会不会是SLB的问题,先测试一下不通过SLB直接访问,查看日志
100.97.90.213 - - [30/Jun/2017:10:44:09 +0800] "GET /api/v1/saleorder?dataSource=&salesStatus=01&shopNo=&carrierAssignStatus=&creTimeBegin=
2017-06-30+00:00:00&creTimeEnd=2017-06-30+23:59:59&salesNo=&status=&carrierStatus=&warehouseStatus=&dataTranslateStatus=&buyerAccount=&changeBuyer=-1
&changeSeller=-1&platformOrderTime=&platformOrderEndTime=&confirmPayTime=&confirmPayEndTime=&receiverMobile=&receiverProvince=&receiverCity=&
receiverArea=&referenceNo=&receiverName=&page=1&pageSize=50&__preventCache=1498790641974 HTTP/1.1" 200 105705 "https://erp-uat.jiuyescm.com/"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
日志果然出现了HTTP/1.1,这个让我们找到了希望,但是还有个区别,直接访问走的是ip+port普通的http,slb访问走的是域名而且是ssl,这个会不会跟ssl有关系,于是查询了ssl的http版本支持情况排除了这个问题,那就是继续往SLB上怀疑,翻阿里云负载均衡的说明文档。
让我找到了说明,查看如下信息

找了半天原来是SLB强制转换了协议版本,具体查看阿里云负载均衡的常见问题
问题没有解决,需要咨询阿里云工作人员看对于这类问题是否有好的解决方法,问题持续跟踪
跟阿里云客服沟通后,官方人员建议使用长连接通过slb的tcp协议,我们当初为了ssl方便配置slb选择的是http和https,因此就需要修改部署的结构
- 删除原有的slb
- 增加一个新的slb,协议选择tcp,添加两个端口监听,80-xxxx,443-xxxx
- 域名绑定的ip切换到新创建的slb
- nginx中添加ssl-module,添加ssl证书配置,添加http跳转到https,调整80-xxxx,443-xxxx
重启nginx进行测试
测试通过

采用这种部署方式来解决nginx 502问题
