Lombok使用说明
一、项目背景
在写Java程序的时候经常会遇到如下情形:
新建了一个Class类,然后在其中设置了几个字段,最后还需要花费很多时间来建立getter和setter方法
lombok项目的产生就是为了省去我们手动创建getter和setter方法的麻烦,它能够在我们编译源码的时候自动帮我们生成getter和setter方法。即它最终能够达到的效果是:在源码中没有getter和setter方法,但是在编译生成的字节码文件中有getter和setter方法
比如源码文件:
import java.io.Serializable;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Data
@Slf4j
@NoArgsConstructor
@AllArgsConstructor
public class TestUserVo implements Serializable{
private static final long serialVersionUID = -5648809805573016853L;
private Long id;
private Long userId;
/**
* 获取 id
* @return the id
*/
public Long getId() {
System.out.println("getId");
return id;
}
/**
* 设置 id
* @param id the id to set
*/
public void setId(Long id) {
System.out.println("setId");
this.id = id;
}
}
以下是编译上述源码文件得到的字节码文件,对其反编译得到的结果
import java.io.Serializable;
import java.beans.ConstructorProperties;
import java.io.PrintStream;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TestUserVo implements Serializable {
public String toString() {
return "TestUserVo(id=" + getId() + ", userId=" + getUserId() + ")";
}
public int hashCode() {
int PRIME = 59;
int result = 1;
Object $id = getId();
result = result * 59 + ($id == null ? 43 : $id.hashCode());
Object $userId = getUserId();
result = result * 59 + ($userId == null ? 43 : $userId.hashCode());
return result;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public boolean equals(Object o) {
if (o == this) {
return true;
}
if (!(o instanceof TestUserVo)) {
return false;
}
TestUserVo other = (TestUserVo) o;
if (!other.canEqual(this)) {
return false;
}
Object this$id = getId();
Object other$id = other.getId();
if (this$id == null ? other$id != null : !this$id.equals(other$id)) {
return false;
}
Object this$userId = getUserId();
Object other$userId = other.getUserId();
return this$userId == null ? other$userId == null : this$userId.equals(other$userId);
}
protected boolean canEqual(Object other) {
return other instanceof TestUserVo;
}
private static final Logger log = LoggerFactory.getLogger(TestUserVo.class);
private static final long serialVersionUID = -5648809805573016853L;
private Long id;
private Long userId;
@ConstructorProperties({ "id", "userId" })
public TestUserVo(Long id, Long userId) {
this.id = id;
this.userId = userId;
}
public Long getUserId() {
return this.userId;
}
public Long getId() {
System.out.println("getId");
return this.id;
}
public void setId(Long id) {
System.out.println("setId");
this.id = id;
}
public TestUserVo() {
}
}
为什么推荐使用它呢,因为我们一般写一个pojo时很容易遗漏(equals、toString、hashCode、canEqual)这几个方法,使用Lombok不但可以在编译的时候自动生成getter、setter方法还会根据字段来生成(equals、toString、hashCode、canEqual)这几个方法.
Lombok在生成getter、setter方法时不会覆盖我们源码中已经编写的getter、setter方法,所以可以大胆的使用。
下面介绍几个常用的 lombok 注解:
@Data :注解在类上;提供类所有属性的 getting 和 setting 方法,此外还提供了equals、canEqual、hashCode、toString 方法
@Setter:注解在属性上;为属性提供 setting 方法
@Getter:注解在属性上;为属性提供 getting 方法
@Log4j | @Slf4j | @Log :注解在类上;为类提供一个 属性名为log 的 log4j | SLF4j | Log(java logging)日志对象
@NoArgsConstructor:注解在类上;为类提供一个无参的构造方法
@AllArgsConstructor:注解在类上;为类提供一个全参的构造方法
其他的查看官网的文档:https://projectlombok.org/features/all
二、使用方法
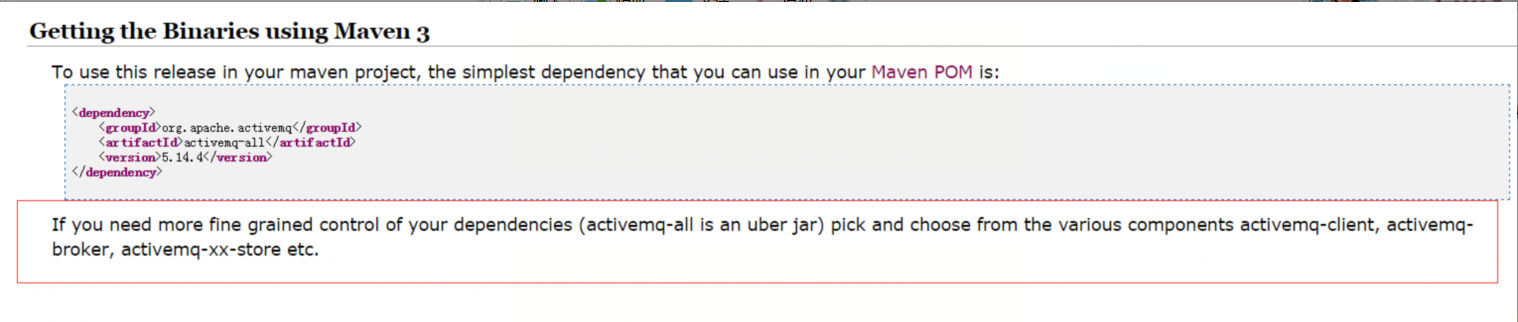
Maven依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>lombok</version>
</dependency>
ps.版本为:1.16.18,并且scope为:provided,我们只在编译时使用。
使用lombok项目的方法很简单,分为四个步骤:
1)在需要自动生成类上,加上自动生成注解(@Data、@Setter、@Getter、@Log4j、@Slf4j、@Log、@NoArgsConstructor、@AllArgsConstructor,等等)
2)在编译类路径中加入lombok.jar包 ,maven中添加依赖
3)使用支持lombok的编译工具编译源代码(关于支持lombok的编译工具,见“四、支持lombok的编译工具”)
4)编译得到的字节码文件中自动生成相应配置的代码
三、原理分析
接下来进行lombok能够工作的原理分析,以Oracle的javac编译工具为例。
自从Java 6起,javac就支持“JSR 269 Pluggable Annotation Processing API”规范,只要程序实现了该API,就能在javac运行的时候得到调用。
举例来说,现在有一个实现了”JSR 269 API”的程序A,那么使用javac编译源码的时候具体流程如下:
1)javac对源代码进行分析,生成一棵抽象语法树(AST)
2)运行过程中调用实现了”JSR 269 API”的A程序
3)此时A程序就可以完成它自己的逻辑,包括修改第一步骤得到的抽象语法树(AST)
4)javac使用修改后的抽象语法树(AST)生成字节码文件
详细的流程图如下:
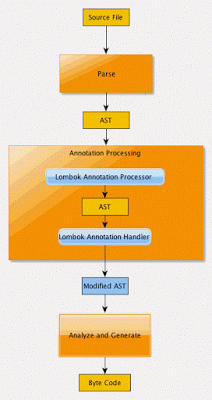
lombok本质上就是这样的一个实现了”JSR 269 API”的程序。在使用javac的过程中,它产生作用的具体流程如下:
1)javac对源代码进行分析,生成一棵抽象语法树(AST)
2)运行过程中调用实现了”JSR 269 API”的lombok程序
3)此时lombok就对第一步骤得到的AST进行处理,找到@Data注解所在类对应的语法树(AST),然后修改该语法树(AST),增加getter和setter方法定义的相应树节点
4)javac使用修改后的抽象语法树(AST)生成字节码文件
四、支持lombok的编译工具
- 由“三、原理分析”可知,
Oraclejavac直接支持lombok - 常用的项目管理工具
Maven所使用的java编译工具来源于配置的第三方工具,如果我们配置这个第三方工具为Oraclejavac的话,那么Maven也就直接支持lombok了 - Intellij Idea中配置,可以下载安装Intellij Idea中的”Lombok plugin”。
- Eclipse中配置lombok支持(或者使用官方的plugin:https://projectlombok.org/setup/eclipse)
- 去官网下载:http://projectlombok.org/
- eclipse / myeclipse 手动安装
lombok - 将 lombok.jar 复制到 myeclipse.ini / eclipse.ini 所在的文件夹目录下
- 打开 eclipse.ini / myeclipse.ini,在最后面插入以下两行并保存:
-Xbootclasspath/lombok.jar -javaagent:lombok.jar- 重启 eclipse / myeclipse
如上配置后,在类以后用上无需书写
getter、setter程序中也可以直接引用getter、setter方法 其他IDE支持,请去官网:https://projectlombok.org/ 点击Install选择不同的IDE插件安装说明
五、lombok的罪恶
使用lombok虽然能够省去手动创建setter和getter方法的麻烦,但是却大大降低了源代码文件的可读性和完整性,降低了阅读源代码的舒适度。
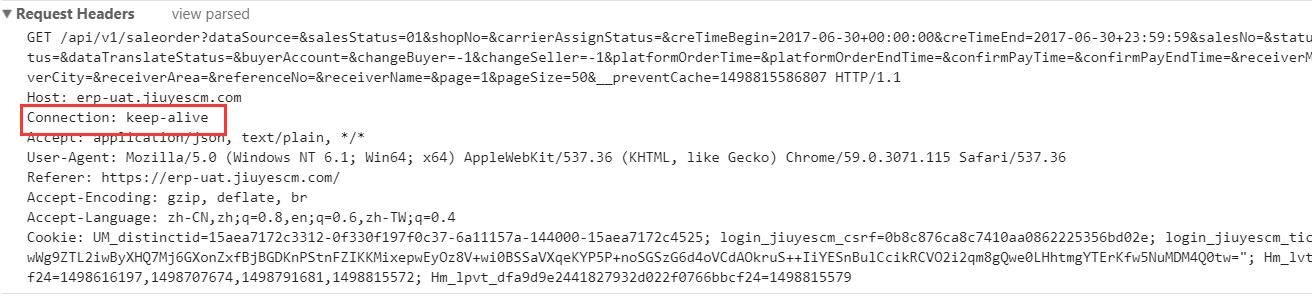 那问题出在哪里?我们应该知道前端请求如果设置为长连接必须要服务端也支持长连接才行,难道是服务器上没有配置长连接导致的?
那问题出在哪里?我们应该知道前端请求如果设置为长连接必须要服务端也支持长连接才行,难道是服务器上没有配置长连接导致的?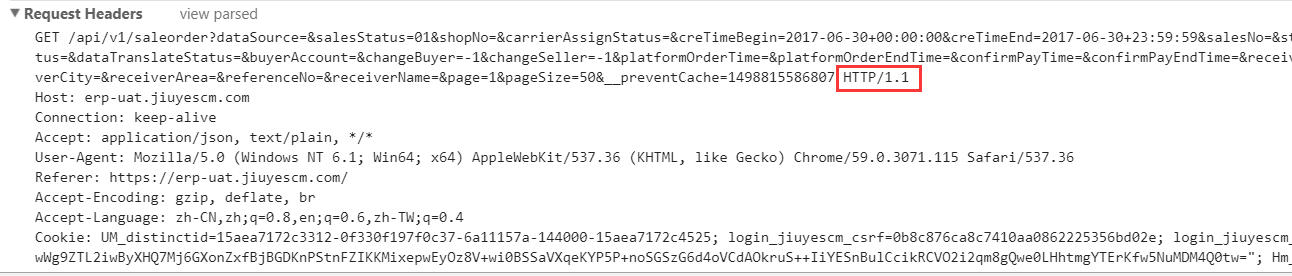 请求的明明是HTTP 1.1为什么到nginx中成了HTTP 1.0?
请求的明明是HTTP 1.1为什么到nginx中成了HTTP 1.0?

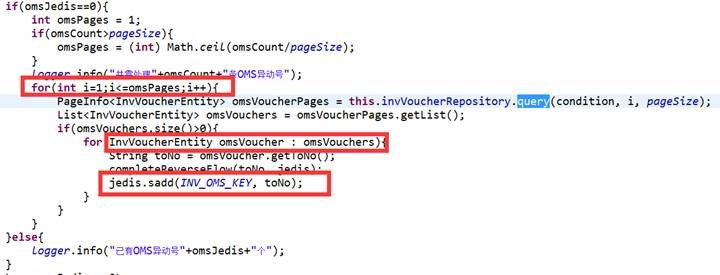 【正例】
【正例】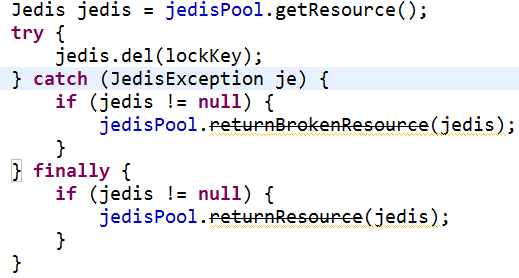 【正例】
【正例】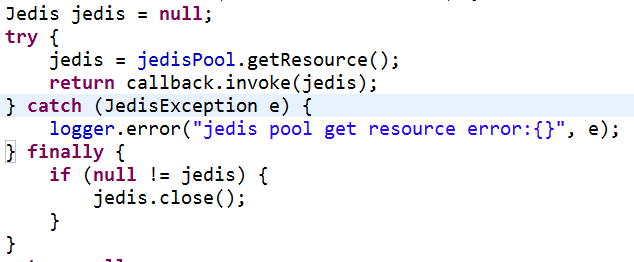
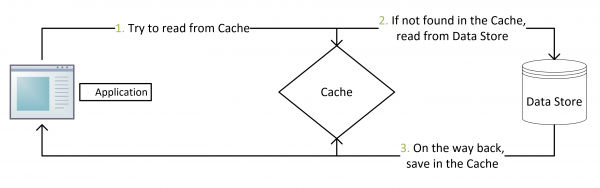
 Write Behind Caching Pattern
Write Behind Caching Pattern
 修改corePoolSize之后
修改corePoolSize之后