博客迁移
由于旧的站点分类、标签、归档中没有分页,也无法搜索本站内的博文,移动端支持的不好,所以现在将站点迁移到https://ningyu1.github.io
新的博客显示风格更加友好,支持移动端显示,支持搜索本站内的所有博文,首页、归档、分类、标签均支持分页,支持分享到wechat、qq、weibo等。
Peace yo. 谢谢

由于旧的站点分类、标签、归档中没有分页,也无法搜索本站内的博文,移动端支持的不好,所以现在将站点迁移到https://ningyu1.github.io
新的博客显示风格更加友好,支持移动端显示,支持搜索本站内的所有博文,首页、归档、分类、标签均支持分页,支持分享到wechat、qq、weibo等。
Peace yo. 谢谢
在开发中我们经常会用到对象之间的互相拷贝,Java中对象拷贝的类库也比较多,常见的有Spring BeanUtils,Apache BeanUtils,等并且在很多大厂公司对对象拷贝也有详尽的说明,避免大家踩坑。
| 耗时(毫秒) | 1000次 | 10,000次 | 100,100次 |
|---|---|---|---|
Apache BeanUtils |
298 | 983 | 4211 |
Cglib BeanCopier |
89 | 120 | 203 |
Spring BeanUtils |
92 | 160 | 524 |
| Apache BeanUtils | Cglib BeanCopier | Spring BeanUtils | |
|---|---|---|---|
| 非public类 | 不支持 | 支持 | 支持 |
| 基本类型与装箱类型,int->Integer,Integer->int | 支持,可以copy | 不支持,不copy | 不支持,不copy |
| int->long,long->int,int->Long,Integer->long | 不支持 | 不支持 | 不支持 |
| 源对象相同属性无get方法 | 不支持 不copy | 不支持 不copy | 不支持 不copy |
| 目标对象相同属性无get方法 | 支持 | 不支持 | 支持 |
| 目标对象相同属性无set方法 | 不copy,不报错 | 报错 | 不copy,不报错 |
| 源对象相同属性无set方法 | 支持 | 支持 | 支持 |
| 目标对象相同属性set方法返回非void | 不设置,其他正常属性可以copy | 不设置,导致其他属性都无法copy | 支持,能够copy |
| 目标对象多字段 | 支持 | 支持 | 支持 |
| 目标对象少字段 | 支持 | 支持 | 支持 |
从性能对比来看:
cglib的BeanCopier最好, Spring BeanUtils稍微差点,但也还可以,Apache BeanUtils性能最差cglib 在set方法返回非void时,会导致其他属性无法copy,目标没有set方法时,会报错,还存在并且有多项不支持的情况从公司内网转载一篇同事整理的资料,关于前后端分离的优劣方面,整理的比较全面,推荐不明白为什么要前后端分离的同学阅读。
首先说明:前后端分离并非仅仅只是一种开发模式,而是一种架构模式(前后端分离架构)。
| 序号 | 老的开发模式(后端以Java为例) | 新的开发模式(后端以Java为例) |
|---|---|---|
| 1 | 产品经理/领导/客户提出需求 | 产品经理/领导/客户提出需求 |
| 2 | UI做出设计图 | UI做出设计图 |
| 3 | 前端工程师做html页面 | 前后端约定接口&数据&参数 |
| 4 | 后端工程师将html页面套成jsp页面 | 前后端并行开发 |
| 5 | 集成出现问题 前端返工 后端返工 | 前后端集成 |
| 6 | 二次集成 集成成功 交付 | 前端页面调整 集成成功 交互 |
| 序号 | 老的开发模式(后端以Java为例) | 新的开发模式(后端以Java为例) |
|---|---|---|
| 1 | 客户端请求 | 浏览器发送请求 |
| 2 | 服务端的servlet或controller接收请求 | 直接到达html页面(前端控制路由与渲染页面,整个项目开发的权重前移) |
| 3 | 调用service,dao代码完成业务逻辑 | html页面负责调用服务端接口产生数据 |
| 4 | 返回jsp jsp展现一些动态的代码 | 填充html,展现动态效果,在页面上进行解析并操作DOM或数据 |
| 序号 | 优势 |
|---|---|
| 1 | 可以实现真正的前后端解耦,前端服务器使用nginx,后端/应用服务器使用tomcat,加快整体响应速度 |
| 2 | 发现bug,可以快速定位是谁的问题,不会出现互相踢皮球的现象 |
| 3 | 减少后端服务器的并发/负载压力 |
| 4 | 即使后端服务暂时超时或者宕机了,前端页面也会正常访问,只不过数据刷不出来而已 |
| 5 | 多端应用 |
| 6 | 页面显示的东西再多也不怕,因为是异步加载 |
| 7 | 增加代码的维护性&易读性 |
| 8 | 提升开发效率,因为可以前后端并行开发,而不是像以前的强依赖 |
| 9 | 前端大量的组件代码得以复用,组件化,提升开发效率,抽出来 |
| 10 | 在nginx中部署证书,外网使用https访问,并且只开放443和80端口,其他端口一律关闭(防止黑客端口扫描),内网使用http,性能和安全都有保障。 |
| 11 | nginx支持页面热部署,不用重启服务器,前端升级更无缝。 |
| 12 | 前端项目中可以加入mock测试(构造虚拟测试对象来模拟后端,可以独立开发和测试) |
有联调、沟通环节,这个过程非常花时间,也容易出bug,还很难维护。
后端: 把精力放在 高并发,高可用,高性能,安全,存储,业务等等研究上
例如:设计模式,原理及源码,事务隔离与锁机制,http/tcp,多线程,分布式架构,弹性计算架构,微服务架构,性能优化,以及相关的项目管理等等
前端: 把精力放在页面表现,速度流畅,兼容性,用户体验等等
例如:html5,css3,jquery,angularjs,reactjs,vuejs,webpack,less/sass,gulp,nodejs,Google V8引擎,javascript多线程,模块化,面向切面编程,设计模式,浏览器兼容性,性能优化等等
| 序号 | 总结 |
|---|---|
| 1 | 前后端分离并非仅仅只是一种开发模式,而是一种架构模式(前后端分离架构)。 |
| 2 | 千万不要以为只有在撸代码的时候把前端和后端分开就是前后端分离了,需要区分前后端项目。 |
| 3 | 前端项目与后端项目是两个项目,放在两个不同的服务器,需要独立部署,两个不同的工程,两个不同的代码库,不同的开发人员。 |
| 4 | 前后端工程师需要约定交互接口,实现并行开发,开发结束后需要进行独立部署,前端通过ajax来调用http请求调用后端的restful api。 |
| 5 | 前端只需要关注页面的样式与动态数据的解析&渲染,而后端专注于具体业务逻辑。 |
今天我们谈一下开发团队代码质量如何做到管控与提升,我相信很多公司都会面临这样的问题,开发团队大人员技术水平参差不齐,代码写的不够规范,代码扫描问题修改太过滞后,代码库管理每个团队都不一致,偶尔还会合并丢失一些代码,code review费人费时效率不高,开发任务的管理以及任务与代码的可追溯问题,等等之类的问题,我们能否制定一套从设计到开发再到交付一整套的管控方案来帮助开发团队管控代码的质量?下来我就针对这些问题展开来谈谈我的想法。
比如说我们要增加代码和任务之间的可追溯性,我们可能考虑采用git+jira关联的方式对开发人员每笔提交在提交comment中增加jira编号,这是就是一个规范,但是规范落地如何检查?开发人员如果忘记在comment中添加就会造成关联失败,那我们就要采用工具的方式帮助开发人员在提交时检查comment是否符合规范。
比如说我们有制定编码规范,也采用了sonar去扫描代码的问题,但是这个方式的缺点是太过滞后,需要质量人员跟进去推动并且效果也不是很好,我们是否可以考虑前置检查点帮助开发人员在代码编写和提交时能主动的发现问题,在代码提交的时候发现规范问题可以直接进行解决再提交,我们可以考虑采用git加checkstyle、pmd、fingbug等工具插件,在代码提交的时候进行规范检测并且进行告警,这样就可以很好的帮助开发人员及时的发现问题,并不是开发已经提交了再去sonar上检查代码规范来发现问题再事后的安排人员去解决,开发人员都有一个习惯,当功能开发好没有问题后他们很少会去主动的修改与重构代码,这样就会导致迟迟不能推进,我们提前了检查点帮助开发人员及时发现问题就可以更好的推行规范的落地。
因此我们要考虑提供一整套代码质量管理的机制,应用在开发全生命周期中,并在关键的流程节点进行验证,从而把控与提升代码的质量。
我相信大多都会使用类似sonar这类的静态代码检查工具来检查代码,这里我们不说工具的好坏,我们只说检查问题的修复情况,我相信很多开发都会有一种习惯,在代码写完之后如果上线没有问题的话他们是很少会去主动的优化代码,即使你扫描结果告诉他他也会有各种理由推脱,当然我们可以通过管理的手段强制他们修改,比如说blocker、critical级别的必须全部改掉,其余的看情况修改,当然通过管理手段从上往下会有一定的效果,但是这些都是比较滞后的方式,我们能不能提前发现问题让开发在功能开发过程中就把发现的问题改掉?
这个当然是可以的,我们可以利用代码检查的机制,在代码开发中就让开发去扫描发现问题,在代码提交的时候去校验如果有严重的禁止代码提交。这样一来我们就可以提前来发现并解决问题,这样可能会带来的是开发人员的排斥,开发人员都觉得自己代码写的没有问题,所以这块我们需要把控这个检查规则的宽松度,我们可以结合公司的开发规范,整理不同级别的问题,通过先简后严的方式,先把开发的习惯培养起来后再逐渐的提升严格度,这样一来开发就有个适应期也比较好接受,比如说:我们通过checkstyle的规则模板定义,前期把一些无用导入包、命名不规范、导入包用*、system.out语句这类接受度高的作为error级别来推动开发适应从而培养这种良好的习惯。
在技术行业做了一定时间的人应该都知道code review是多么的重要,一可以促进团队人员之间互相交流,二可以提升整体团队的技术水平,学习优秀人员写的代码,帮助初级人员提升代码编写能力,所以code review还是强烈必须要做的,至于怎么做code review?我谈一下我的想法和建议
比较常见的方式是定期团队内组织全体人员进行集中式的code review,我比较推荐利用工具在线的操作方式来做code review,现在开源非常的火也可以参考学习开源团队code review的方式,比如说github有pull request,gitlab有merge request,可以在这个合并代码的节点上进行code review,这样做的好处是第一比较开放,只要能看到合并代码请求的都可以进行review,第二可以留下review记录,互相的想法沟通和建议可以很好的留存下来并且可以通过UI的方式友好的展示出来,从而提升code review效率。
这个当然需要结合git flow的机制来协作完成。
团队多了或团队大了,每个人或多或少对git的管理与使用理解不一致,这样就造成了分支、版本管理的混乱,这样在版本代码合并时就会产生很多冲突,我们可以指定一套规范性的东西,指导开发团队进行分支、版本的管理,这里说到的是指导不是限制,要让开发在可控的范围内自由发挥。
可以参考git flow、github flow等,当然我们要统一一个工作流程推广给开发团队中。
前面我们说了用代码合并来进行code review,这样我们就要让开发人员在每开发完一个任务的时候就要进行一次代码合并,git是一个优秀的分布式代码库管理工具,我们利用git的分布式特性,以及灵活的流程机制来规范大家的使用。
例如:
一次迭代冲刺或一个版本对应一个develop-*分支和release-*,并且控制分支的push与merge权限,固定一个master分支并且控制master分支的权限,让个人开发通过feature-{username|功能名称}-*分支来进行功能开发,当一个任务或者一个功能开发完成进行一次develop-*分支的合并,这样一来及可以code review也可以有序的管理分支上的代码,当开发人员提交合并请求时发生了冲突就需要开发人员自己解决完冲突后再进行代码合并请求,这样一来版本分支上代码是有序的。
| Name | From | Remark |
|---|---|---|
master |
- | 只能有一个并并且固定的 |
develop-* |
从master创建 | 开发分支,可以结合jira的sprint,一个sprint对应一个,迭代开始时创建,’*’ 通常可以是一个发布周期或者一个冲刺命名 |
release-* |
从master创建 | 预发布分支,可以结合jira的sprint,一个sprint对应一个,迭代开始时创建,’*’ 通常可以是一个发布周期或者一个冲刺命名 |
feature-{username or 功能名称}-* |
从develop-*创建 |
开发人员分支,这个分支的声明周期很短,在这个功能开发完成通过Merge Request发起合并进行code review之后合并从而删除分支 |
以上可以定位分支约定。
具体的操作可以参考下面描述:
master创建develop分支,例如是develop-V1.2.0develop分支创建自己的feature分支进行开发master分支发生变更,需要从master分支合并到对应的develop分支、可以考虑定期合并一次feature分支合并到对应的develop之前,需要从develop分支合并到feature分支(这个避免和其他人提交进行冲突,规范开发人员自己解决掉冲突后才能发起合并请求)feature分支合并到对应的develop之后,发布到测试环境进行测试(测试环境直接使用对应的develop分支)develop分支在测试环境测试通过之后,合并到对应的release分支并发布到预发布环境(UAT)进行测试release分支在预发布环境(UAT)验证通过后,合并到master分支并发布到生产环境进行验证master分支构建对应的版本tag可同时支持多个sprint的并行。
代码的提交备注非常重要,尤其是在合并代码时产生冲突,第一时间肯定是根据提交日期去看本次提交做了什么修改,如果说备注随便填写,或者有些都没有填这样在回头来看的时候,及时是提交本人他也不能第一时间看出具体做了哪些修改,因此我觉得作为一个开发人员提交备注写的清晰明了是一件必备的职业素养,至于一些不按照规范的技术人员我们也可以要求他们按照规范必须填写。
那如何做到对备注填写的质量把控呢?我们可以通过版本管理工具在提交代码时进行提交备注检测,比如说对长度的限制,至少要15个字符,或者对格式做一些验证,必须包含任务编号之类,这样一来就可以有效的控制代码提交备注的质量以及可读性。
我们现在常用的git就有hook机制可以提供在代码提交前后做一些钩子,利用钩子来控制允许提交或者拒绝提交,比如说git的pre-commit和commit-msg
优秀的开发人员主动性都是很好的,主动性对开发来说也是非常重要的职业素养,不要让人催促你来完成任务,自己要学会主动找任务去做主动想如何优化与提升,所以时间任务管理是非常重要的,我任务开发人员都应该具备自己的时间任务管理能力,无论用什么工具只要能管理跟踪好自己的任务就是不错的人员。
公司一般都有任务管理工具,有的用禅道、有的用jira,现在用jira的相对多一些,jira的功能丰富也可以促进团队进行敏捷的任务管理,我们可以通过打通任务管理工具和代码版本工具,让代码提交的时候通过任务编号产生关联,从而可以在任务中看到代码修改的片段。
这里我用jira+git举个例子,比如说我们利用jira做scrum的敏捷管理,在制定好epic、story、task、subtask后,可以通过scrum模型的管理手段,在开发过程中通过插件、图标的数据来分析是否有风险?那个人的任务delay?那个人的任务制定还可以再进行拆分?等,从而尽早的做出调整来控制整个迭代周期按时完成。利用git提交的备注写入jira编号,通过jira和git的插件打通任务与提交代码的关联,这样一来我们就可以很好的看到任务执行过程数据与具体改动了哪些代码,从而提升开发效率。
我们上面说到的利用了checkstyle来验证代码风格,通过git hook来控制提交备注的规范,这些都需要自定义一些脚本,这些脚本也应该利用git进行有效的管理,我们能力能做到统一的调整了规则与脚本,开发过程中的应用立即使用最新的验证规则?还有git hooks的脚本是在开发机器本地运行的,这样就带来了一个问题如何让开发去安装脚本呢?叫他们手动安装?写个bat或shell脚本让开发执行一次?
我觉得更好的方式是对开发透明在他们不知觉的时候已经悄悄的安装,我们可以利用git对规则与脚本的版本进行管理,利用nginx可以通过http方式直接访问规则与脚本文件,通过自定义maven plugin在代码build的时候验证开发机器上是否已经安装,如果没有就给它自动安装与自动更新。
这样我们只要修改了规则与脚本后进行版本发布,开发机就会自动的更新下来从而可以立即生效。
很多公司开发团队一味的满头苦干,很容易忽视团队内的技术分享,再加上团队内人员进进出出有一些正能量的人当然也有一些负能量的人,这都是常事,但是不管怎样我相信做技术的人都愿意提升自己的技术能力,不管是工作中实践学习还是说参加沙龙或者论坛,都是很好的学习渠道,人的精力也是比较有限不可能关注很多面,通过团队内的技术分享,把每个人擅长的部分分享给大家,互相学习来提升凝聚力和团队整体的技术水平,这样长期以来我相信团队内的技术氛围肯定不会差。
以上就是我对代码质量管理与提升方面的经验与思考,里面涉及到很多东西,有流程的制定、工具的协作、工具的打通、规范的制定等,因此这是一个系统性的方案,希望可以利用一整套代码质量管理的流程,在关键的流程节点来把控代码的质量,形成闭环,希望可以帮助有需要的人,如果有更好的建议也希望大家多提意见进行补充,没有完美的方式,只有找到适合的可落地的就是好的。
这篇文章转自公司内网wiki中一篇不错的问题分析文章,
问题点是在第一个事务抛异常回滚了,第一个表成功回滚,但是第二个事务将第一个事务中的第二个表的数据提交了。
基于上面6点, 当第一个事务的第一个表执行是失败后(在第一个表的失败位置上设置一个savepoint,回滚时值回滚到这个savepoint,第二个preparestatement被缓存了)
注意:PreparedStatement确实适合执行相同sql的批处理,Statement适合执行不同sql的批处理
一些代码跟踪截图这里就不方便放出来请见谅。
RESTful开发时经常会遇到参数传入日期类型及返回的日期类型值,日期和时间戳如果没有适当和一致地处理,就会给人带来头痛的问题,我这里建议大家使用统一格式化的时间字符串yyyy-MM-dd HH:mm:ss,为什么建议这个呢?这样看起来比较直观,前后端联调起来比较高效。
下面我们就细说一下日期类型的参数将如何处理。
举例
url如下:
http://localhost:8081/test/time_get?time=2018-07-09 10:38:57
Controller代码:
import java.util.Date;
@RequestMapping(value = "/time_get", method = RequestMethod.GET)
@ResponseBody
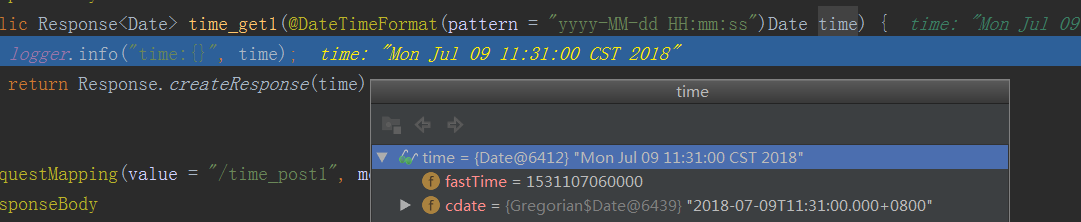
public Response<Date> time_get(Date time) {
logger.info("time:{}", time);
return Response.createResponse(time);
}
在这种情况下日期参数是无法成功的传入到controller方法里,会爆出如下的异常:
org.springframework.core.convert.ConversionFailedException: Failed to convert from type java.lang.String to type java.util.Date for value '2018-07-09 10:38:57'; nested exception is java.lang.IllegalArgumentException
at org.springframework.core.convert.support.ObjectToObjectConverter.convert(ObjectToObjectConverter.java:81) ~[spring-core-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.core.convert.support.ConversionUtils.invokeConverter(ConversionUtils.java:35) ~[spring-core-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.core.convert.support.GenericConversionService.convert(GenericConversionService.java:178) ~[spring-core-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.beans.TypeConverterDelegate.convertIfNecessary(TypeConverterDelegate.java:161) ~[spring-beans-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.beans.TypeConverterDelegate.convertIfNecessary(TypeConverterDelegate.java:93) ~[spring-beans-4.0.0.RELEASE.jar:4.0.0.RELEASE]
at org.springframework.beans.TypeConverterSupport.doConvert(TypeConverterSupport.java:64) ~[spring-beans-4.0.0.RELEASE.jar:4.0.0.RELEASE]
... 43 common frames omitted
Caused by: java.lang.IllegalArgumentException: null
at java.util.Date.parse(Date.java:615) ~[na:1.7.0_45]
at java.util.Date.<init>(Date.java:272) ~[na:1.7.0_45]
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[na:1.7.0_45]
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) ~[na:1.7.0_45]
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[na:1.7.0_45]
at java.lang.reflect.Constructor.newInstance(Constructor.java:526) ~[na:1.7.0_45]
at org.springframework.core.convert.support.ObjectToObjectConverter.convert(ObjectToObjectConverter.java:76) ~[spring-core-4.0.0.RELEASE.jar:4.0.0.RELEASE]
... 48 common frames omitted
那如何解决上面的问题?使用@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")加到日期参数之前,像下面那样使用一样。
Controller代码:
import java.util.Date;
@RequestMapping(value = "/time_get", method = RequestMethod.GET)
@ResponseBody
public Response<Date> time_get(@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") Date time) {
logger.info("time:{}", time);
return Response.createResponse(time);
}
提示:年月日:pattern=“yyyy-MM-dd”,年月日时分秒:pattern=“yyyy-MM-dd HH:mm:ss”
请求体:
GET /test/time_get1?time=2018-07-09 11:31:00 HTTP/1.1
Host: localhost:8081
后端接收到的信息,debug截图:
当使用@RequestBody接受一个VO对象时@DateTimeFormat就会失效,因为我们走的是Json序列化与反序列化,@DateTimeFormat只会生效与object序列化、反序列化。如果使用的Spring可以自定义messageConvert或者增强MappingJackson2HttpMessageConverter中的ObjectMapper
代码如下:
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
@Configuration
public class WebConfig extends WebMvcConfigurationSupport {
@Override
protected void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
List<HttpMessageConverter<?>> messageConverters = new ArrayList<HttpMessageConverter<?>>();
addDefaultHttpMessageConverters(messageConverters);
for (int i = 0; i < messageConverters.size(); i++) {
HttpMessageConverter<?> mc = messageConverters.get(i);
if (mc instanceof MappingJackson2HttpMessageConverter) {
ObjectMapper objectMapper = new ObjectMapper();
//当json中属性在反序列化时,javabean中没有找到属性就忽略,如果FAIL_ON_UNKNOWN_PROPERTIES=true找不到属性会报错
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
//设置序列化、反序列化时日期类型的格式
objectMapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
((MappingJackson2HttpMessageConverter) mc).setObjectMapper(objectMapper);
}
converters.add(mc);
}
}
}
注意:使用Jackson进行json序列化反序列化,默认可以处理yyyy-MM-dd这个格式,但是反序列化后的时间会差8小时
通过上面对json序列化反序列化的配置后日期参数处理就变的简单了,效果如下。
Controller代码:
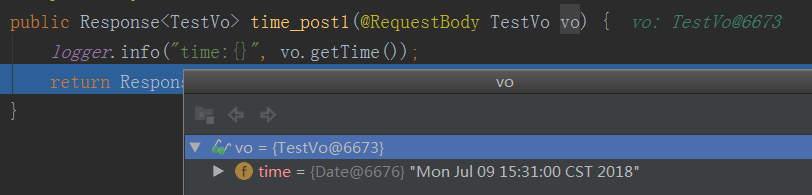
@RequestMapping(value = "/time_post", method = RequestMethod.POST)
@ResponseBody
public Response<Date> time_post(@RequestBody TestVo vo) {
logger.info("time:{}", vo.getTime());
return Response.createResponse(vo.getTime());
}
VO代码:
public class TestVo implements Serializable {
private static final long serialVersionUID = 7435595656552442126L;
private Date time;
public Date getTime() {
return time;
}
public void setTime(Date time) {
this.time = time;
}
}
提示:VO中无需使用@DateTimeFormat,就是一个普通的javabean即可
请求体:
POST /test/time_post HTTP/1.1
Host: localhost:8081
Content-Type: application/json
{
"time":"2018-07-09 15:31:00"
}
后端接收到的信息,debug截图
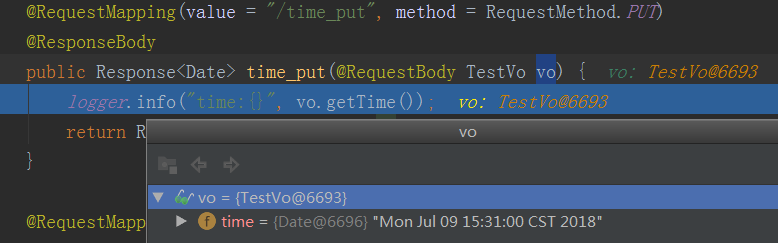
如果put传参方式与get一样在方法上直接传参(url?time=2018-07-09 10:38:57),那参考get请求参数处理方式即可
如果put传参方式与post一样使用@RequestBody传入json格式数据,那么参考post请求参数处理方式即可
请求体:
PUT /test/time_put HTTP/1.1
Host: localhost:8081
Content-Type: application/json
{
"time":"2018-07-09 15:31:00"
}
后端接收到的信息,debug截图
前面都说的是request时日期格式处理方式,那么我们继续说一下response时日期格式如何处理。
SpringMVC使用@ResponseBody时,日期格式默认显示为时间戳,不管方法直接返回Date类型、或者VO类型时,时间格式都一样返回时间戳,例如这样。
请求体:
POST /test/time_post1 HTTP/1.1
Host: localhost:8081
Content-Type: application/json
{
"time":"2018-07-09"
}
响应体:
{
"code": "",
"message": "",
"items": {
"time": 1531094400000
}
}
那如果我们要以字符串格式返回呢,那该如何处理?
方法一增加统一的messageConvert处理:
如果使用的spring可以自定义messageConvert或者增强MappingJackson2HttpMessageConverter中的ObjectMapper
代码在POST方法时参数传入日期类型该如何处理这个章节
方法二通过@JsonFormat注解处理:
请在VO对象的date字段上加上@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone = "GMT+8"),例如下面代码:
VO代码:
public class TestVo implements Serializable {
private static final long serialVersionUID = 7435595656552442126L;
@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")
private Date time;
public Date getTime() {
return time;
}
public void setTime(Date time) {
this.time = time;
}
}
注意:@JsonFormat(pattern=“yyyy-MM-dd HH:mm:ss”,timezone = “GMT+8”) ,即可将json返回的对象为指定的类型。
返回日期格式使用的是”yyyy-MM-dd HH:mm:ss”样式字符串示例:
请求体:
POST /test/time_post1 HTTP/1.1
Host: localhost:8081
Content-Type: application/json
{
"time":"2018-07-09 15:31:00"
}
响应体:
{
"code": "",
"message": "",
"items": {
"time": "2018-07-09 15:31:00"
}
}
这里有的人喜欢使用时间戳,有的人喜欢使用统一格式化的时间字符串yyyy-MM-dd HH:mm:ss,我个人的建议使用后者,因为这样比较直观调试交流起来也比较方便。
使用哪种没有对错,其实就是一种规范,统一规范可以提升协作效率,因此我建议的规范如下:
这些都是我个人摸爬滚打多年码出来的心得体会,说的不好还请见谅,希望可以帮助有需要的人。
我们经常会遇到项目中很多对表单进行自定义,比如说saas应用针对租户自定义表单字段名称,自定义列表名称。 还有更高级自定义,比如说自定义的模块,表单、字段、字段类型、流程等自定义。
提供自定义也是一个系统扩展性的体现,自定义功能的强大自然能适应更多的用户场景。
接下来我们就看看自定义的实现方案通常都有哪些方式。
常见的自定义字段的实现方式分为三种由简到繁,扩展性、复杂性也是逐渐增强的,每个方式各有优劣解决的场景也有所不同,具体往下看。
模型如下:
| ID | Name | Ext1(性别) | Ext2(地区) | Ext3(QQ) | Ext4(WECHAT) |
|---|---|---|---|---|---|
| 1 | 韩梅梅 | 女 | Shanghai | 10000 | |
| 2 | 李磊 | 男 | Beijing | abc001 |
优点:
缺点:
对象属性存储在一个有三列的表中:实体,属性和值(entity,attribute,value)。实体(entiry)表示所描述的数据项,例如一个产品或汽车。属性(attribute)表示描述实体的数据,例如一个产品将有价格,重量和许多其他属性。值(value)是属性的值,例如产品可能有一个9.99英镑的价格属性。此外值可以基于数据类型进行分割,所以可将EAV表分为字符串、整数、日期和长文本(long text)表。依据数据类型分割是为了支持索引,使得数据库执行可能的类型检查验证。
EAV表模型带来了数据的灵活性,是的增加对象的属性不需要用增加数据库的字段,有很高的灵活性。但是EAV表也有较大的性能问题。通常,EAV表带来的一个问题是当查找多个字段时,需要进行关联查询join,这样的查询效率比较低。为了提高查询效率,我们可以对商品属性表进行矩阵转积处理(pivoting)。
一种方式是在代码中读出后存入cache中,当修改attributes表后触发更新cache或用cron定期更新;另一种方法是将关联信息组成一张大的临时表,数据的更新可以用数据库的触发器触发更新。由于大量数据在代码中进行处理会带来了DB的额外IO和服务器性能问题。当使用EAV表模型时,InnoDB比MYISAM的性能要好不少。
ps. 我们常用的行模型(纵向)存储就是EAV模型实现的一种方式。
模型如下:
人员表(Entity)
| ID | Name |
|---|---|
| 1 | 韩梅梅 |
| 2 | 李磊 |
扩展映射(Entities)
| Entity | Attribute | Value |
|---|---|---|
| 1 | sex(性别) | 女 |
| 2 | sex(性别) | 男 |
| 1 | region(地区) | Shanghai |
| 2 | region(地区) | Beijing |
| 1 | 10000 | |
| 2 | abc001 |
优点:
缺点:
json格式非常丰富,在描述自定义字段的这方面比较适合,可以把一行多列的数据压缩到一个json text内,也比较节省空间,json格式可以无限扩展,还可支持多个自定义字段有不同的格式。
模型如下:
| ID | Name | Content |
|---|---|---|
| 1 | 韩梅梅 | {“sex”:“女”,“region”:“Shanghai”,“QQ”:“10000”} |
| 2 | 李磊 | {“sex”:“女”,“region”:“Beijing”,“WECHAT”:“abc001”} |
ps. 支持以上的两种不同的自定义格式并存

优点:
缺点:
数据库对Json类型的支持:
数据库对json类型的检索支持:
ORM框架对Json类型的支持:
Mysql5.7.x json操作官方文档:
Mysql5.7.x 注意事项:
实现方式不局限于上面说到的方式,有更好的方式欢迎留言进行沟通。
原文地址: https://jeffhuang.com/best_paper_awards.html
我擦好牛逼了,自1996年起的计算机科学最佳论文奖全收录,不说了戳开看吧。
最近看到了一篇分析雪花算法的文章还不错,然后整理了一下分享出来。
先来科普一下SnowFlake算法
Twitter Snowflake 生成的 unique ID 的组成 (由高位到低位):
41 bits: Timestamp (毫秒级) 10 bits: 节点 ID (datacenter ID 5 bits + worker ID 5 bits) 12 bits: sequence number 一共 63 bits (最高位是 0).
unique ID 生成过程:
41-bit的时间可以表示(1L<<41)/(1000L x 3600 x 24 x 365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
优缺点这里就不赘述了。
那我们继续看一个经典的Java版本的实现,这个在网上一搜一大把,官方原版的Scala版本
public class Snowflake {
private static final Logger logger = LoggerFactory.getLogger(Snowflake.class);
/**
* 机器ID
*/
private final long workerId;
/**
* 时间起始标记点,作为基准,一般取系统的最近时间,默认2017-01-01
*/
private final long epoch = 1483200000000L;
/**
* 机器id所占的位数(源设计为5位,这里取消dataCenterId,采用10位,既1024台)
*/
private final long workerIdBits = 10L;
/**
* 机器ID最大值: 1023 (从0开始)
*/
private final long maxWorkerId = -1L ^ -1L << this.workerIdBits;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = this.sequenceBits;
/**
* 时间戳向左移22位(5+5+12)
*/
private final long timestampLeftShift = this.sequenceBits + this.workerIdBits;
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095),12位
*/
private final long sequenceMask = -1L ^ -1L << this.sequenceBits;
/**
* 并发控制,毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间戳
*/
private long lastTimestamp = -1L;
private final int HUNDRED_K = 100_000;
/**
* @param workerId 机器Id
*/
private Snowflake(long workerId) {
if (workerId > this.maxWorkerId || workerId < 0) {
String message = String.format("worker Id can't be greater than %d or less than 0", this.maxWorkerId);
throw new IllegalArgumentException(message);
}
this.workerId = workerId;
}
/**
* Snowflake Builder
* @param workerId workerId
* @return Snowflake Instance
*/
public static Snowflake create(long workerId) {
return new Snowflake(workerId);
}
/**
* 批量获取ID
* @param size 获取大小,最多10万个
* @return SnowflakeId
*/
public long[] nextId(int size) {
if (size <= 0 || size > HUNDRED_K) {
String message = String.format("Size can't be greater than %d or less than 0", HUNDRED_K);
throw new IllegalArgumentException(message);
}
long[] ids = new long[size];
for (int i = 0; i < size; i++) {
ids[i] = nextId();
}
return ids;
}
/**
* 获得ID
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 如果上一个timestamp与新产生的相等,则sequence加一(0-4095循环);
if (this.lastTimestamp == timestamp) {
// 对新的timestamp,sequence从0开始
this.sequence = this.sequence + 1 & this.sequenceMask;
// 毫秒内序列溢出
if (this.sequence == 0) {
// 阻塞到下一个毫秒,获得新的时间戳
timestamp = this.tilNextMillis(this.lastTimestamp);
}
} else {
// 时间戳改变,毫秒内序列重置
this.sequence = 0;
}
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < this.lastTimestamp) {
String message = String.format("Clock moved backwards. Refusing to generate id for %d milliseconds.", (this.lastTimestamp - timestamp));
logger.error(message);
throw new RuntimeException(message);
}
this.lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return timestamp - this.epoch << this.timestampLeftShift | this.workerId << this.workerIdShift | this.sequence;
}
/**
* 等待下一个毫秒的到来, 保证返回的毫秒数在参数lastTimestamp之后
* @param lastTimestamp 上次生成ID的时间戳
* @return
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 获得系统当前毫秒数
*/
private long timeGen() {
return System.currentTimeMillis();
}
}
那让我们看一下代码来理解一下算法的细节。
我们从关键的代码段来理解,如下:
this.sequence = this.sequence + 1 & this.sequenceMask;
private final long maxWorkerId = -1L ^ -1L << this.workerIdBits;
return ((timestamp - this.epoch) << this.timestampLeftShift)
| (this.workerId << this.workerIdShift)
| this.sequence;
ps. 我这里取消了datacenterId,将datacenterId和workerid合并到workerIdBits
在计算机中,负数的二进制是用补码来表示的。 假设我是用Java中的int类型来存储数字的, int类型的大小是32个二进制位(bit),即4个字节(byte)。(1 byte = 8 bit) 那么十进制数字3在二进制中的表示应该是这样的:
00000000 00000000 00000000 00000011
// 3的二进制表示,就是原码
那数字-3在二进制中应该如何表示? 我们可以反过来想想,因为-3+3=0, 在二进制运算中把-3的二进制看成未知数x来求解, 求解算式的二进制表示如下:
00000000 00000000 00000000 00000011 //3,原码
+ xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx //-3,补码
-----------------------------------------------
00000000 00000000 00000000 00000000
反推x的值,3的二进制加上什么值才使结果变成00000000 00000000 00000000 00000000?:
00000000 00000000 00000000 00000011 //3,原码
+ 11111111 11111111 11111111 11111101 //-3,补码
-----------------------------------------------
1 00000000 00000000 00000000 00000000
反推的思路是3的二进制数从最低位开始逐位加1,使溢出的1不断向高位溢出,直到溢出到第33位。然后由于int类型最多只能保存32个二进制位,所以最高位的1溢出了,剩下的32位就成了(十进制的)0。
补码的意义就是可以拿补码和原码(3的二进制)相加,最终加出一个“溢出的0”
以上是理解的过程,实际中记住公式就很容易算出来:
补码 = 反码 + 1 补码 = (原码 - 1)再取反码 因此-1的二进制应该这样算:
00000000 00000000 00000000 00000001 //原码:1的二进制
11111111 11111111 11111111 11111110 //取反码:1的二进制的反码
11111111 11111111 11111111 11111111 //加1:-1的二进制表示(补码)
具体对位运算以及二进制的计算理解可以看看这篇文章https://blog.csdn.net/cj2580/article/details/80980459
